Mar 31 Take the State of DevOps Survey 2021 By CD Foundation Blog, Staff It's the tenth year that Puppet runs the State of DevOps Survey and we’re happy to be a part of it! 🎉Read More
Mar 26 How do you really measure DevOps success? By tracymiranda Blog, Staff Are your adoption efforts of Continuous Delivery and DevOps practices successful? Find out!Read More
Mar 25 CA Endevor – A History Lesson for Today’s DevOps Pipelines By CD Foundation Blog, Community Where do Continuous Delivery and Continuous Integration come from?Read More
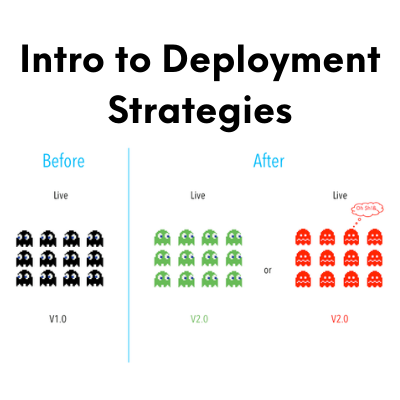
Mar 24 Intro to Deployment Strategies: Blue-Green, Canary, and More By CD Foundation Blog, Member This post explores the different deployment strategies and practices to help you succeed with your production deployments.Read More
Mar 23 GitOps Summit Hosted by CD Foundation and Cloud Native Computing Foundation By cdfoundation Announcement, Blog, Staff GitOps Summit will be co-located with cdCon on June 22, 2021. Registration is free.Read More
Mar 22 How to Sign a Release of OSS By CD Foundation Blog, Community What does it mean to sign a release? Who should do it? Where should the keys live? How do users verify it? Why are we even doing this again?Read More
Mar 19 CD Foundation’s Governing Board – 2021 Goals By tracymiranda Blog, Staff The CDF Governing Board set the Foundation’s goals for 2021: End User, Brand and Projects.Read More
Mar 16 CD Foundation Announces Industry Initiative to Standardize Events from CI/CD Systems By CD Foundation Announcement, Blog Introducing the Events SIG: a vendor-neutral, open effort to drive the standardization and interoperability between Continuous Delivery systems through events.Read More
Mar 12 CDF & Google Summer of Code (GSoC) By CD Foundation Blog, Staff CCF is a Google Summer of Code 2021 mentor organization! We'll start accepting proposals on March 29, 2021.Read More
Mar 08 CDF Spring Elections – Nominations Now Open By CD Foundation Blog, Staff The Continuous Delivery Foundation is holding elections for a set of various positions throughout the foundation.Read More