
Tekton Hub is a central location for users to discover a curated set of contributed resources from the Community Catalog. Try it out!
Read More

Originally posted on the Harness.io blog by Tiffany Jachja (@tiffanyjachja)
In an organization where developers are continuously pushing code to production, managing risks can be difficult. In Measuring and Managing Information Risk: A FAIR Approach, Jack Freund and Jack Jones describe governance as a cost-effective approach to “govern the organization’s risk landscape.” You want to ensure your organization actively understands and manages risk, especially in heavily regulated industries expected to comply with governing authorities and standards, see compliance, or a blog post on measuring compliance.
Governance, risk management, and compliance (GRC) is an umbrella term covering an organization’s approach across these three practices: governance, risk management, and compliance. Freund and Jones describe risk and compliance.
“This [the risk] objective is all about making better-informed risk decisions, which boils down to three things: (1) identifying ‘risks,’ (2) effectively rating and prioritizing ‘risks,’ and (3) making decisions about how to mitigate ‘risks’ that are significant enough to warrant mitigation.”
“Of the three objectives, compliance management is the simplest—at least on the surface. On the surface, compliance is simply a matter of identifying the relevant expectations (e.g., requirements defined by Basel, Payment Card Industry (PCI), SOX, etc.), documenting and reporting on how the organization is (or is not) complying with those expectations, and tracking and reporting on activities to close any gaps.”
So if GRC is about aligning an organization to managing risks, what role do developers play?
We discussed in the previous blog posts the importance of taking a systematic approach to developing software delivery processes. We shared practices like Value Stream Mapping, to give organizations the tools to better understand their value streams and to accelerate their DevOps journey. These DevOps practices indicate that every software delivery stakeholder is responsible for the value they deliver. But on the flip side, they also indicate that stakeholders are responsible for any risks that they create or introduce.
The DevOps Automated Governance Reference Architecture found here, shares how to further adopt a systems approach to delivery.

By looking at each stage in your delivery pipeline, you can define the inputs, outputs, actors, actions, risks, and control points related to that stage.

The essential part of governance is that developers are aware of the risks at each stage. The reference architecture paper shares some of the common risks associated with code commits, such as unapproved changes and PII or credentials in source code. Likewise, for deploying to production, you can have risks such as low-quality code in production, lack of quality gates, and unexpected system behaviors in production.
These risks help define areas of control points that help manage that risk. If you face the risk of unapproved changes, introduce a change approval process. Likewise, you can control risks through secrets management, application quality analysis, quality gate evaluation, and enforced deployment strategies.
Everyone involved in the process from code commits to production is responsible for mitigating risks.
Now let’s discuss the components of a governance process for a cloud environment. The DevOps Automated Governance Reference Architecture, found here, shares an approach to navigating your automated governance journey. Many of these concepts to be discussed here are explained in detail in that reference paper.
Notes are metadata definitions. Occurrences are generated for each artifact or resource that needs this note. As an example, a note could provide details of a specific vulnerability, such as the impacts, names, and status. I would generate an occurrence for every container image with that security vulnerability. Similarly, I could have a note that defines a specific application deployment, as I promote the deployment across different environments, I would generate an occurrence. There is a one to many relationships between notes and occurrences.
An attestation is a particular type of note that represents a verification that you’ve satisfied in your governance process. Attestations are tied to attestors, which hold the authority to verify a control point within your governance process. For example, determining you’ve passed a code review or a unit test is an attestation. Each attestation represents a control point within your governance process.
A binary authorization policy uses a list of attestors to represent your governance as code. A binary auth policy acts as a series of gates so that you can not get to the next stage of your software delivery before getting an attestation from each attestor. Therefore, it’s common practice to turn on binary authorization (BinAuthz) in your Kubernetes environment to ensure you are governing changes and deployments. You’ll have an Admission Controller in your Google Kubernetes Engine(GKE) that does the checks for attestation when you go interact with your environment. Here’s more information on how BinAuthz works for GKE.
If you’d like to learn more about designing control points for your governance process, Captial One also shared their pipeline design through a concept called “16 Gates” in a blog post called “Focusing on the DevOps Pipeline.”
Governance processes require automation to accelerate software delivery; otherwise, it can harm your velocity and time to market. A popular topic to emerge in the past year is automated pipeline governance, which gives enterprises the ability to attest to the integrity of assets in a delivery pipeline. Pipeline governance goes beyond traditional CICD, where developers simply automate delivery without truly mitigating risk. Continuous Integration and Continuous Delivery platforms can help heavily regulated industries manage their governance processes when developers and operations understand the organization’s risks.
Tekton Pipelines, the major component in an open-source project for CI/CD (continuous integration and continuous delivery) on Kubernetes, has reached the milestone of beta status.
Tekton was originally Knative Build, what was then one of three major components in the Knative project, the others being serving and eventing. In June 2019, Knative Build was deprecated in favour of Tekton Pipelines. A Tekton pipeline runs tasks, where each task consists of steps running on a container in a Kubernetes pod.
By Tracy Ragan, CEO of DeployHub, CD Foundation Board Member
Microservice pipelines are different than traditional pipelines. As the saying goes…
“The more things change; the more things stay the same.”
As with every step in the software development evolutionary process, our basic software practices are changing with Kubernetes and microservices. But the basic requirements of moving software from design to release remain the same. Their look may change, but all the steps are still there. In order to adapt to a new microservices architecture, DevOps Teams simply need to understand how our underlying pipeline practices need to shift and change shape.
The key to understanding microservices is to think ‘functions.’ With a microservice environment the concept of an ‘application’ goes away. It is replaced by a grouping of loosely coupled services connected via APIs at runtime, running inside of containers, nodes and pods. The microservices are reused across teams increasing the need for improved organization (Domain Driven Design), collaboration, communication and visibility.
The biggest change in microservice pipeline is having a single microservice used by multiple application teams independently moving through the life cycle. Again, one must stop thinking ‘application’ and think instead think ‘functions’ to fully appreciate the oncoming shift. And remember, multiple versions of a microservice could be running in your environments at the same time.
Microservices are immutable. You don’t ‘copy over’ the old one, you deploy a new version. When you deploy a microservice, you create a Kubernetes deployment YAML file that defines the Label and the version of the image.
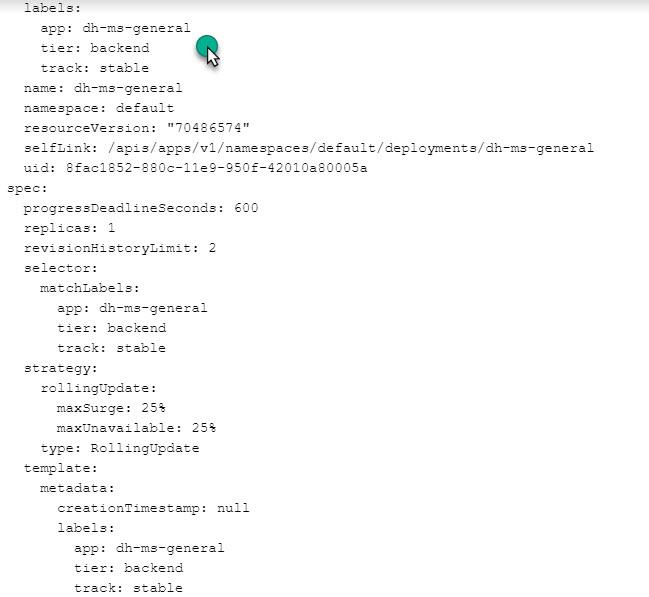
In the above example, our Label is dh-ms-general. When a microservice Label is reused for a new container image, Kubernetes stops using the old image. But in some cases, a second Label may be used allowing both services to be running at the same time. This is controlled by the configuration of your ingresses. Our new pipeline process must incorporate these new features of our modern architecture.
What does your life cycle pipeline look like when we manage small functions vs. a monolithic applications running in a modern architecture? Below is a comparison for each category and their potential shift for supporting a microservice pipeline.
Monolithic:
Logging a user problem ticket, enhancement request or anomaly based on an application.
Microservices:
This process will remain relatively un-changed in a microservice pipeline. Users will continue to open tickets for bugs and enhancements. The difference will be sorting out which microservice needs the update, and which version of the microservice the ticket was opened against. Because a microservice can be used by multiple applications, dependency management and impact analysis will become more critical for helping to determine where the issue lies.
Monolithic:
Tracking changes in source code content. Branching and merging updates allowing multiple developers to work on a single file.
Microservices:
While versioning your microservice source code will still be done, your source code will be smaller, 100-300 lines of code versus 1,000 – 3,000 lines of code. This impacts the need for branching and merging. The concept of merging ‘back to the trunk’ is more of a monolithic concept, not a microservice concept. And how often will you branch code that is a few hundred lines long?
Monolithic:
Originally built around Maven, an artifact repository provides a central location for publishing jar files, node JS Packages, Java scripts packages, docker images, python modules. At the point in time where you run your build your package manager (maven, NPM, PIP) will perform the dependency management for tracking transitive dependencies.
Microservices:
Again, these tools supported monolithic builds and solved dependency management to resolve compile/link steps. We move away from monolithic builds, but we still need to build our container and resolve our dependencies. These tools will help us build containers by determining the transitive dependencies need for the container to run.
Monolithic:
Executes a serial process for calling compilers and linkers to translate source code into binaries (Jar, War, Ear, .Exe, .dlls, docker images). Common languages that support the build logic includes Make, Ant, Maven, Meister, NPM, PIP, and Docker Build. The build calls on artifact repositories to perform dependency management based on what versions of libraries have been specified by the build script.
Microservices:
For the most part, builds will look very different in a microservice pipeline. A build of a microservice will involve creating a container image and resolving the dependencies needed for the container to run. You can think of a container image to be our new binary. This will be a relatively simple step and not involve a monolithic compile/link of an entire application. It will only involve a single microservice. Linking is done at runtime with the restful API call coded into the microservice itself.
Monolithic:
The build process is the central tool for performing configuration management. Developers setup their build scripts (POM files) to define what versions of external libraries they want to include in the compile/link process. The build performs configuration management by pulling code from version control based on a ‘trunk’ or ‘branch. A Software Bill of Material can be created to show all artifacts that were used to create the application.
Microservices:
Much of what we use to do for configuring our application occurred at the software ‘build.’ But ‘builds’ as we know them go away in a microservice pipeline. This is where we made very careful decisions about what versions of source code and libraries we would use to build a version of our monolithic application. For the most part, the version and build configuration shifts to runtime with microservices. While the container image has a configuration, the broader picture of the configuration happens at run-time in the cluster via the APIs.
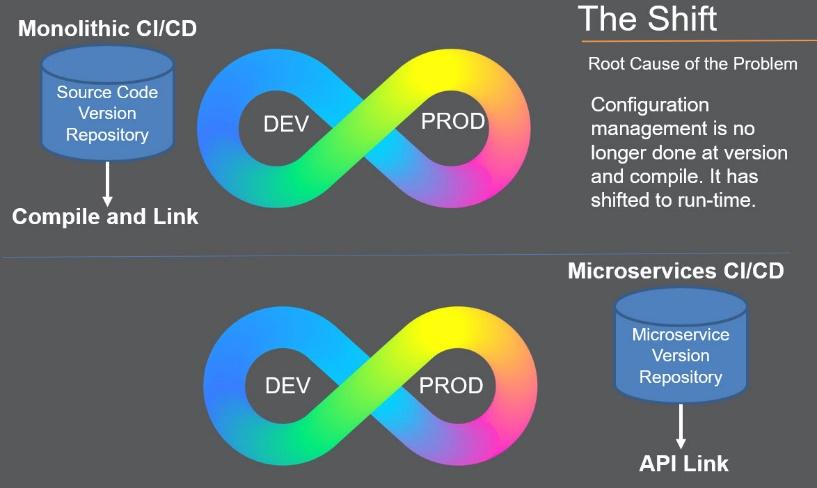
In addition, our SCM will begin to bring in the concept of Domain Driven Design where you are managing an architecture based on the microservice ‘problem space.’ New tooling will enter the market to help with managing your Domains, your logical view of your application and to track versions of applications to versions of services. In general, SCM will become more challenging as we move away from resolving all dependencies at the compile/link step and must track more of it across the pipeline.
Monolithic:
CI is the triggered process of pulling code and libraries from version control and executing a Build based on a defined ‘quiet time.’ This process improved development by ensuring that code changes were integrated as frequently as possible to prevent broken builds, thus the term continuous integration.
Microservices:
Continuous Integration was originally adopted to keep us re-compiling and linking our code as frequently as possible in order to prevent the build from breaking. The goal was to get to a clean ’10-minute build’ or less. With microservices, you are only building a single ‘function.’ This means that an integration build is no longer needed. CI will eventually go away, but the process of managing a continuous delivery pipeline will remain important with a step that creates the container.
Monolithic:
Code scanners have evolved from looking at coding techniques for memory issues and bugs to scanning for open source library usage, licenses and security problems.
Microservices:
Code scanners will continue to be important in a microservice pipeline but will shift to scanning the container image more than the source. Some will be used during the container build focusing on scanning for open source libraries and licensing while others will focus more on security issues with scanning done at runtime.
Monolithic:
Continuous testing was born out of test automation tooling. These tools allow you to perform automated test on your entire application including timings for database transactions. The goal of these tools is to improve both the quality and speed of the testing efforts driven by your CD workflow.
Microservices:
Testing will always be an important part of the life cycle process. The difference with microservices will be understanding impact and risk levels. Testers will need to know what applications depend on a version of a microservice and what level of testing should be done across applications. Test automation tools will need to understand microservice relationships and impact. Testing will grow beyond testing a single application and instead will shift to testing service configurations in a cluster.
Monolithic:
Security solutions allow you to define or follow a specific set of standards. They include code scanning, container scanning and monitoring. This field has grown into the DevSecOps movement where more of the security activities are being driven by Continuous Delivery.
Microservices:
Security solutions will shift further ‘left’ adding more scanning around the creation of containers. As containers are deployed, security tools will begin to focus on vulnerabilities in the Kubernetes infrastructure as they relate to the content of the containers.
Monolithic:
Continuous Delivery is the evolution of continuous integration triggering ‘build jobs’ or ‘workflows’ based on a software application. It auto executes workflow processes between development, testing and production orchestrating external tools to get the job done. Continuous Delivery calls on all players in the lifecycle process to execute in the correct order and centralizes their logs.
Microservices:
Let’s start with the first and most obvious difference between a microservice pipeline and a monolithic pipeline. Because microservices are independently deployed, most organizations moving to a microservice architecture tell us they use a single pipeline workflow for each microservice. Also, most companies tell us that they start with 6-10 microservices and grow to 20-30 microservices per traditional application. This means you are going to have hundreds if not thousands of workflows. CD tools will need to include the ability to template workflows allowing a fix in a shared template to be applied to all child workflows. Managing hundreds of individual workflows is not practical. In addition, plug-ins need to be containerized and decoupled from a version of the CD tool. And finally, look for actions to be event driven, with the ability for the CD engine to listen to multiple events, run events in parallel and process thousands of microservices through the pipeline.
Monolithic:
This is the process of moving artifacts (binaries, containers, scripts, etc.) to the physical runtime environments on a high frequency basis. In addition, deployment tools track where an artifact was deployed along with audit information (who, where, what) providing core data for value stream management. Continuous deployment is also referred to as Application Release Automation.
Microservices:
The concept of deploying an entire application will simply go away. Instead, deployments will be a mix of tracking the Kubernetes deployment YAML file with the ability to manage the application’s configuration each time a new microservice is introduced to the cluster. What will become important is the ability to track the ‘logical’ view of an application by associating which versions of the microservices make up an application. This is a big shift. Deployment tools will begin generating the Kubernetes YAML file removing it from the developer’s to-do list. Deployment tools will automate the tracking of versions of the microservice source to the container image to the cluster and associated applications to provide the required value stream reporting and management.
As we shift from managing monolithic applications to microservices, we will need to create a new microservice pipeline. From the need to manage hundreds of workflows in our CD pipeline, to the need for versioning microservices and their consuming application versions, much will be different. While there are changes, the core competencies we have defined in traditional CD will remain important even if it is just a simple function that we are now pushing independently across the pipeline.

Tracy Ragan is CEO of DeployHub and serves on the Continuous Delivery Foundation Board. She is a microservice evangelist with expertise in software configuration management, builds and release. Tracy was a consultant to Wall Street firms on build and release management for 7 years prior to co-founding OpenMake Software in 1995. She was a founding member of the Eclipse organization and served on the board for 5 years. She is a recognized leader and has been published in multiple industry publications as well as presenting to audiences at industry conferences. Tracy co-founded DeployHub in 2018 to serve the microservice development community.
Another 6 weeks, another Tekton release. It’s mostly common knowledge that Tekton’s logo is a robot cat, but it’s lesser known that the releases are named after robots and cats! Each Tekton Pipelines release is given a codename of a type of cat followed by a famous robot.
On Monday, December 2nd, Andrea Frittoli of IBM cut the v0.9.0 release, dubbed “Bengal Bender”. This release contained commits from 21 different individuals. I wanted to take the time to highlight some of the new features and API changes, as well as to point out what much of the “under the covers” work is laying the groundwork for.
So let’s jump in!
“Bengal Bender” includes a solid set of features, bug fixes and performance improvements. Apologies if I missed anything here, this list is simply what I find most exciting.
https://github.com/tektoncd/pipeline/pull/1432
If you were at Kubecon San Diego you might have come away with the impression that Go is the language of the cloud. And while that is true to some extent, good old bash and yaml also play a huge part, especially when it comes to “glue” systems like delivery pipelines.
If you’ve spent much time working with containers, you’ve probably seen a yaml file with something like this in it:
- name: hello
image: ubuntu
command: ['bash']
args:
- -c
- |
set -ex
echo "hello"This is a lot of complicated boilerplate just to run a simple bash script inside a container. And if you’re not deeply familiar with how bash, shells, entrypoints and shebangs all work at the system level, this is a bit opaque. It’s also prone to subtle and confusing bugs. Even if you are familiar with these things, you’ve probably wasted time debugging issues when the shell in your container is set to something you’re not used to, or the entrypoint is overridden, or “bash -c” doesn’t do what you expect.
This makes delivery pipelines harder to write, understand and maintain.
Enter script mode! Inspired by some ideas from Ahmet Alp Balkan, Jason Hall put together a proposal to make it much easier to define tasks that just need to run a simple bash script. Here’s what it looks like:
- name: hello image: ubuntu script: | #!/bin/bash echo "hello"
You’ll notice that there are far fewer lines of boilerplate. No more need to specify args, an entrypoint or remember the tricky “-c” part. Just specify the interpreter you want to use and the commands to run. This has already let us simplify dozens of test cases and examples!
https://github.com/tektoncd/pipeline/pull/1545
Tekton has long suffered from poor performance around starting PipelineRuns. Christie Wilson and I did a debugging/coding session last spring to try to improve this, and identified PVC mounting as a major contributor. Unfortunately, our attempted fix didn’t work and needed to be rolled back.
A more general longer term fix is being handled by Scott Seaward and the re-resources effort, but I decided to take another stab at a short term fix. Fingers crossed that it works, but initial testing shows improvements of anywhere between 5 and 20 seconds per PipelineRun!
There have been a few changes to the API as we start to firm things up for a beta release. We’re hoping to get the majority of these breaking changes in over the next few releases so users can start to build production systems on top of stable versions.
The breaking changes in v0.9.0 include:
Tekton currently provides a mechanism to store the digests of container images built by Tasks. This mechanism predated the PipelineResource subsystem, and required Task authors to write these digests to a specific location at /builder/image-outputs. This change moves that to the standard path for output resources, at /workspace/output/<resource-name>.
Cluster PipelineResources make deploying and working with Kubernetes clusters from within Tasks simple. They provide mechanisms for users to declare where a cluster endpoint is and how to authenticate with it. Then, during Task execution, they automatically configure a .kubeconfig file so Kubernetes tooling can find that cluster. This release contained a few changes to make these cluster resources easier to work with.
Previously, users had to specify a name parameter twice: once in the resource name and once as a parameter to the resource. The second parameter has been removed.

Following the age-old programming advice above, most of the work contained in each Tekton release is in service of features that won’t be exposed until a later release. Digging into the commit log shows a detailed picture of what the community is working toward.
Here’s my editorialized version of what’s coming soon 🙂
A lot of work went into cleaning up the existing PipelineResource subsystem, including the interface exposed to PipelineResource types and the types themselves. Getting these both solid will form the basis for the larger Re-resources effort, which is currently underway. This project will make the resource types extensible, allowing anyone to add and use their own types. It will also hopefully leave us with some embeddable components, so that other systems can make use of Tekton PipelineResources and the coming catalog.
One of the most important steps in shipping a stable API is figuring out how to make changes in a backwards compatible way. No API is perfect, so the ability to upgrade one is paramount. Vincent Demeester and his colleagues at Red Hat have been hard at work designing and implementing an API versioning system that will allow users to upgrade Tekton API versions without breaking existing workloads. This will be key to the coming beta release.
The Tekton project has been amazing to watch grow. This post only details the changes in the Tekton Pipelines release, but there has also been some awesome work done in the Triggers, CLI and Dashboard projects. Triggers now support out-of-the-box Github and Gitlab validation. The CLI has improved support for creating PipelineResources and starting Tasks interactively. Visualization is coming soon to the Dashboard! I’d like to thank everyone that has made Tekton what it is today.
The Tekton community has been hard at work shipping the right APIs and components to build cloud-native software delivery systems. If you’re using Tekton, or interested in learning more about Tekton, we’d love to hear from you. Please consider joining the community, becoming a Tekton Friend or contributing directly.