

By Tracy Ragan, CEO of DeployHub, CD Foundation Board Member
Microservice pipelines are different than traditional pipelines. As the saying goes…
“The more things change; the more things stay the same.”
As with every step in the software development evolutionary process, our basic software practices are changing with Kubernetes and microservices. But the basic requirements of moving software from design to release remain the same. Their look may change, but all the steps are still there. In order to adapt to a new microservices architecture, DevOps Teams simply need to understand how our underlying pipeline practices need to shift and change shape.
Understanding Why Microservice Pipelines are Different
The key to understanding microservices is to think ‘functions.’ With a microservice environment the concept of an ‘application’ goes away. It is replaced by a grouping of loosely coupled services connected via APIs at runtime, running inside of containers, nodes and pods. The microservices are reused across teams increasing the need for improved organization (Domain Driven Design), collaboration, communication and visibility.
The biggest change in microservice pipeline is having a single microservice used by multiple application teams independently moving through the life cycle. Again, one must stop thinking ‘application’ and think instead think ‘functions’ to fully appreciate the oncoming shift. And remember, multiple versions of a microservice could be running in your environments at the same time.
Microservices are immutable. You don’t ‘copy over’ the old one, you deploy a new version. When you deploy a microservice, you create a Kubernetes deployment YAML file that defines the Label and the version of the image.
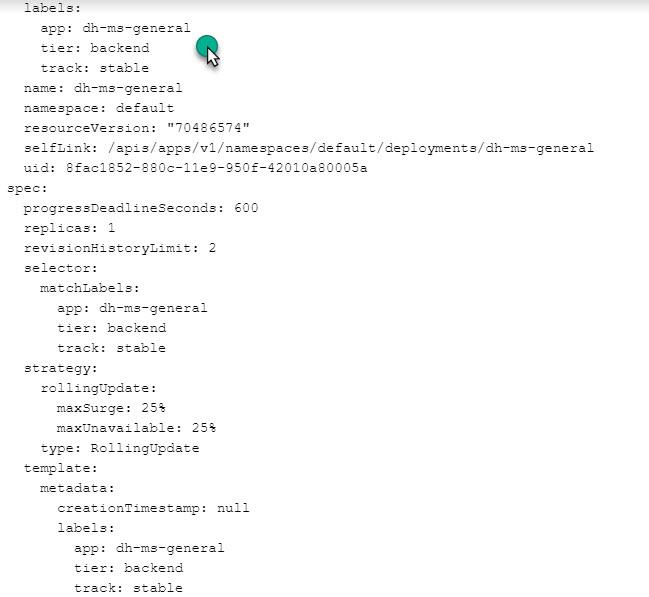
In the above example, our Label is dh-ms-general. When a microservice Label is reused for a new container image, Kubernetes stops using the old image. But in some cases, a second Label may be used allowing both services to be running at the same time. This is controlled by the configuration of your ingresses. Our new pipeline process must incorporate these new features of our modern architecture.
Comparing Monolithic to Microservice Pipelines
What does your life cycle pipeline look like when we manage small functions vs. a monolithic applications running in a modern architecture? Below is a comparison for each category and their potential shift for supporting a microservice pipeline.
Change Request
Monolithic:
Logging a user problem ticket, enhancement request or anomaly based on an application.
Microservices:
This process will remain relatively un-changed in a microservice pipeline. Users will continue to open tickets for bugs and enhancements. The difference will be sorting out which microservice needs the update, and which version of the microservice the ticket was opened against. Because a microservice can be used by multiple applications, dependency management and impact analysis will become more critical for helping to determine where the issue lies.
Version Control
Monolithic:
Tracking changes in source code content. Branching and merging updates allowing multiple developers to work on a single file.
Microservices:
While versioning your microservice source code will still be done, your source code will be smaller, 100-300 lines of code versus 1,000 – 3,000 lines of code. This impacts the need for branching and merging. The concept of merging ‘back to the trunk’ is more of a monolithic concept, not a microservice concept. And how often will you branch code that is a few hundred lines long?
Artifact Repository
Monolithic:
Originally built around Maven, an artifact repository provides a central location for publishing jar files, node JS Packages, Java scripts packages, docker images, python modules. At the point in time where you run your build your package manager (maven, NPM, PIP) will perform the dependency management for tracking transitive dependencies.
Microservices:
Again, these tools supported monolithic builds and solved dependency management to resolve compile/link steps. We move away from monolithic builds, but we still need to build our container and resolve our dependencies. These tools will help us build containers by determining the transitive dependencies need for the container to run.
Builds
Monolithic:
Executes a serial process for calling compilers and linkers to translate source code into binaries (Jar, War, Ear, .Exe, .dlls, docker images). Common languages that support the build logic includes Make, Ant, Maven, Meister, NPM, PIP, and Docker Build. The build calls on artifact repositories to perform dependency management based on what versions of libraries have been specified by the build script.
Microservices:
For the most part, builds will look very different in a microservice pipeline. A build of a microservice will involve creating a container image and resolving the dependencies needed for the container to run. You can think of a container image to be our new binary. This will be a relatively simple step and not involve a monolithic compile/link of an entire application. It will only involve a single microservice. Linking is done at runtime with the restful API call coded into the microservice itself.
Software Configuration Management (SCM)
Monolithic:
The build process is the central tool for performing configuration management. Developers setup their build scripts (POM files) to define what versions of external libraries they want to include in the compile/link process. The build performs configuration management by pulling code from version control based on a ‘trunk’ or ‘branch. A Software Bill of Material can be created to show all artifacts that were used to create the application.
Microservices:
Much of what we use to do for configuring our application occurred at the software ‘build.’ But ‘builds’ as we know them go away in a microservice pipeline. This is where we made very careful decisions about what versions of source code and libraries we would use to build a version of our monolithic application. For the most part, the version and build configuration shifts to runtime with microservices. While the container image has a configuration, the broader picture of the configuration happens at run-time in the cluster via the APIs.
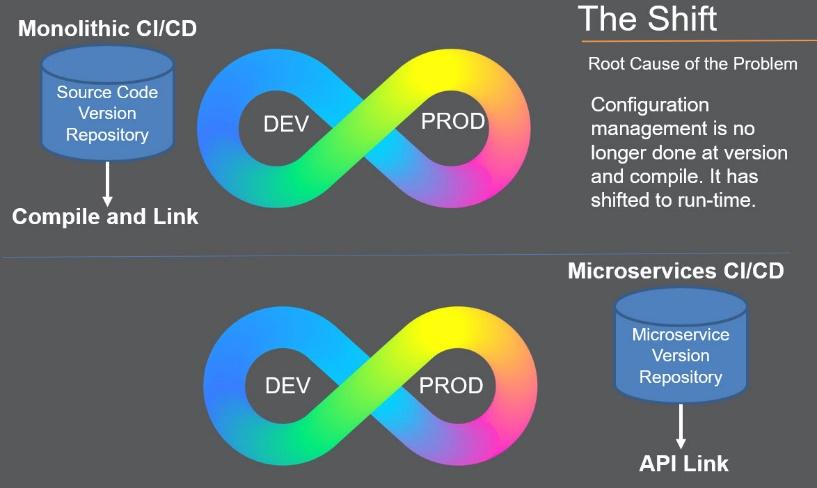
In addition, our SCM will begin to bring in the concept of Domain Driven Design where you are managing an architecture based on the microservice ‘problem space.’ New tooling will enter the market to help with managing your Domains, your logical view of your application and to track versions of applications to versions of services. In general, SCM will become more challenging as we move away from resolving all dependencies at the compile/link step and must track more of it across the pipeline.
Continuous Integration (CI)
Monolithic:
CI is the triggered process of pulling code and libraries from version control and executing a Build based on a defined ‘quiet time.’ This process improved development by ensuring that code changes were integrated as frequently as possible to prevent broken builds, thus the term continuous integration.
Microservices:
Continuous Integration was originally adopted to keep us re-compiling and linking our code as frequently as possible in order to prevent the build from breaking. The goal was to get to a clean ’10-minute build’ or less. With microservices, you are only building a single ‘function.’ This means that an integration build is no longer needed. CI will eventually go away, but the process of managing a continuous delivery pipeline will remain important with a step that creates the container.
Code Scanning
Monolithic:
Code scanners have evolved from looking at coding techniques for memory issues and bugs to scanning for open source library usage, licenses and security problems.
Microservices:
Code scanners will continue to be important in a microservice pipeline but will shift to scanning the container image more than the source. Some will be used during the container build focusing on scanning for open source libraries and licensing while others will focus more on security issues with scanning done at runtime.
Continuous Testing
Monolithic:
Continuous testing was born out of test automation tooling. These tools allow you to perform automated test on your entire application including timings for database transactions. The goal of these tools is to improve both the quality and speed of the testing efforts driven by your CD workflow.
Microservices:
Testing will always be an important part of the life cycle process. The difference with microservices will be understanding impact and risk levels. Testers will need to know what applications depend on a version of a microservice and what level of testing should be done across applications. Test automation tools will need to understand microservice relationships and impact. Testing will grow beyond testing a single application and instead will shift to testing service configurations in a cluster.
Security
Monolithic:
Security solutions allow you to define or follow a specific set of standards. They include code scanning, container scanning and monitoring. This field has grown into the DevSecOps movement where more of the security activities are being driven by Continuous Delivery.
Microservices:
Security solutions will shift further ‘left’ adding more scanning around the creation of containers. As containers are deployed, security tools will begin to focus on vulnerabilities in the Kubernetes infrastructure as they relate to the content of the containers.
Continuous Delivery Orchestration (CD)
Monolithic:
Continuous Delivery is the evolution of continuous integration triggering ‘build jobs’ or ‘workflows’ based on a software application. It auto executes workflow processes between development, testing and production orchestrating external tools to get the job done. Continuous Delivery calls on all players in the lifecycle process to execute in the correct order and centralizes their logs.
Microservices:
Let’s start with the first and most obvious difference between a microservice pipeline and a monolithic pipeline. Because microservices are independently deployed, most organizations moving to a microservice architecture tell us they use a single pipeline workflow for each microservice. Also, most companies tell us that they start with 6-10 microservices and grow to 20-30 microservices per traditional application. This means you are going to have hundreds if not thousands of workflows. CD tools will need to include the ability to template workflows allowing a fix in a shared template to be applied to all child workflows. Managing hundreds of individual workflows is not practical. In addition, plug-ins need to be containerized and decoupled from a version of the CD tool. And finally, look for actions to be event driven, with the ability for the CD engine to listen to multiple events, run events in parallel and process thousands of microservices through the pipeline.
Continuous Deployments
Monolithic:
This is the process of moving artifacts (binaries, containers, scripts, etc.) to the physical runtime environments on a high frequency basis. In addition, deployment tools track where an artifact was deployed along with audit information (who, where, what) providing core data for value stream management. Continuous deployment is also referred to as Application Release Automation.
Microservices:
The concept of deploying an entire application will simply go away. Instead, deployments will be a mix of tracking the Kubernetes deployment YAML file with the ability to manage the application’s configuration each time a new microservice is introduced to the cluster. What will become important is the ability to track the ‘logical’ view of an application by associating which versions of the microservices make up an application. This is a big shift. Deployment tools will begin generating the Kubernetes YAML file removing it from the developer’s to-do list. Deployment tools will automate the tracking of versions of the microservice source to the container image to the cluster and associated applications to provide the required value stream reporting and management.
Conclusion
As we shift from managing monolithic applications to microservices, we will need to create a new microservice pipeline. From the need to manage hundreds of workflows in our CD pipeline, to the need for versioning microservices and their consuming application versions, much will be different. While there are changes, the core competencies we have defined in traditional CD will remain important even if it is just a simple function that we are now pushing independently across the pipeline.
About the Author

Tracy Ragan is CEO of DeployHub and serves on the Continuous Delivery Foundation Board. She is a microservice evangelist with expertise in software configuration management, builds and release. Tracy was a consultant to Wall Street firms on build and release management for 7 years prior to co-founding OpenMake Software in 1995. She was a founding member of the Eclipse organization and served on the board for 5 years. She is a recognized leader and has been published in multiple industry publications as well as presenting to audiences at industry conferences. Tracy co-founded DeployHub in 2018 to serve the microservice development community.