From Dailymotion, a French video-sharing technology platform with over 300 million unique monthly users
At Dailymotion, we are hosting and delivering premium video content to users all around the world. We are building a large variety of software to power this service, from our player or website to our GraphQL API or ad-tech platform. Continuous Delivery is a central practice in our organization, allowing us to push new features quickly and in an iterative way.
We are early adopters of Kubernetes: we built our own hybrid platform, hosted both on-premise and on the cloud. And we heavily rely on Jenkins to power our “release platform”, which is responsible for building, testing, packaging and deploying all our software. Because we have hundreds of repositories, we are using Jenkins Shared Libraries to keep our pipeline files as small as possible. It is an important feature for us, ensuring both a low maintenance cost and a homogeneous experience for all developers – even though they are working on projects using different technology stacks. We even built Gazr, a convention for writing Makefiles with standard targets, which is the foundation for our Jenkins Pipelines.
In 2018, we migrated our ad-tech product to Kubernetes and took the opportunity to set up a Jenkins instance in our new cluster – or better yet move to a “cloud-native” alternative. Jenkins X was released just a few months before, and it seemed like a perfect match for us:
It is built on top and for Kubernetes.
At that time – in 2018 – it was using Jenkins to run the pipelines, which was good news given our experience with Jenkins.
It comes with features such as preview environments which are a real benefit for us.
And it uses the Gitops practice, which we found very interesting because we love version control, peer review, and automation.
While adopting Jenkins X we discovered that it is first a set of good practices derived from the best performing teams, and then a set of tools to implement these practices. If you try to adopt the tools without understanding the practices, you risk fighting against the tool because it won’t fit your practices. So you should start with the practices. Jenkins X is built on top of the practices described in the Accelerate book, such as micro-services and loosely-coupled architecture, trunk-based development, feature flags, backward compatibility, continuous integration, frequent and automated releases, continuous delivery, Gitops, … Understanding these practices and their benefits is the first step. After that, you will see the limitations of your current workflow and tools. This is when you can introduce Jenkins X, its workflow and set of tools.
We’ve been using Jenkins X since the beginning of 2019 to handle all the build and delivery of our ad-tech platform, with great benefits. The main one being the improved velocity: we used to release and deploy every two weeks, at the end of each sprint. Following the adoption of Jenkins X and its set of practices, we’re now releasing between 10 and 15 times per day and deploying to production between 5 and 10 times per day. According to the State of DevOps Report for 2019, our ad-tech team jumped from the medium performers’ group to somewhere between the high and elite performers’ groups.
But these benefits did not come for free. Adopting Jenkins X early meant that we had to customize it to bypass its initial limitations, such as the ability to deploy to multiple clusters. We’ve detailed our work in a recent blog post, and we received the “Most Innovative Jenkins X Implementation” Jenkins Community Award in 2019 for it. It’s important to note that most of the issues we found have been fixed or are being fixed. The Jenkins X team has been listening to the community feedback and is really focused on improving their product. The new Jenkins X Labs is a good example.
As our usage of Jenkins X grows, we’re hitting more and more the limits of the single Jenkins instance deployed as part of Jenkins X. In a platform where every component has been developed with a cloud-native mindset, Jenkins is the only one that has been forced into an environment for which it was not built. It is still a single point of failure, with a much higher maintenance cost than the other components – mainly due to the various plugins.
In 2019, the Jenkins X team started to replace Jenkins with a combination of Prow and Tekton. Prow (or Lighthouse) is the component which handles the incoming webhook events from GitHub, and what Jenkins X calls the “ChatOps”: all the interactions between GitHub and the CI/CD platform. Tekton is a pipeline execution engine. It is a cloud-native project built on top of Kubernetes, fully leveraging the API and capabilities of this platform. No single point of failure, no plugins compatibility nightmare – yet.
Since the beginning of 2020, we’ve started an internal project to upgrade our Jenkins X setup – by introducing Prow and Tekton. We saw immediate benefits:
Faster scheduling of pipelines “runners” pods – because all components are now Kubernetes-native components.
Simpler pipelines – thanks to both the Jenkins X Pipelines YAML syntax and the ability to easily decouple a complex pipeline in multiple small ones that are run concurrently.
Lower maintenance cost.
While replacing the pipeline engine of Jenkins X might seem like an implementation detail, in fact, it has a big impact on the developers. Everybody is used to see the Jenkins UI as the CI/CD UI – the main entry point, the way to manually restart pipelines executions, to access logs and test results. Sure, there is a new UI and a real API with an awesome CLI, but the new UI is not finished yet, and some people still prefer to use web browsers and terminals. Leaving the Jenkins Plugins ecosystem is also a difficult decision because some projects heavily rely on a few plugins. And finally, with the introduction of Prow (Lighthouse) the Github workflow is a bit different, with Pull Requests merges being done automatically, instead of people manually merging when all the reviews and automated checks are green.
So if 2019 was the year of Jenkins X at Dailymotion, 2020 will definitely be the year of Tekton: our main release platform – used by almost all our projects except the ad-tech ones – is still powered by Jenkins, and we feel more and more its limitations in a Kubernetes world. This is why we plan to replace all our Jenkins instances with Tekton, which was truly built for Kubernetes and will enable us to scale our Continuous Delivery practices.
By Tracy Ragan, CEO of DeployHub, CD Foundation Board Member
Microservice pipelines are different than traditional pipelines. As the saying goes…
“The more things change; the more things stay the same.”
As with every step in the software development evolutionary process, our basic software practices are changing with Kubernetes and microservices. But the basic requirements of moving software from design to release remain the same. Their look may change, but all the steps are still there. In order to adapt to a new microservices architecture, DevOps Teams simply need to understand how our underlying pipeline practices need to shift and change shape.
Understanding Why Microservice Pipelines are Different
The key to understanding microservices is to think ‘functions.’ With a microservice environment the concept of an ‘application’ goes away. It is replaced by a grouping of loosely coupled services connected via APIs at runtime, running inside of containers, nodes and pods. The microservices are reused across teams increasing the need for improved organization (Domain Driven Design), collaboration, communication and visibility.
The biggest change in microservice pipeline is having a single microservice used by multiple application teams independently moving through the life cycle. Again, one must stop thinking ‘application’ and think instead think ‘functions’ to fully appreciate the oncoming shift. And remember, multiple versions of a microservice could be running in your environments at the same time.
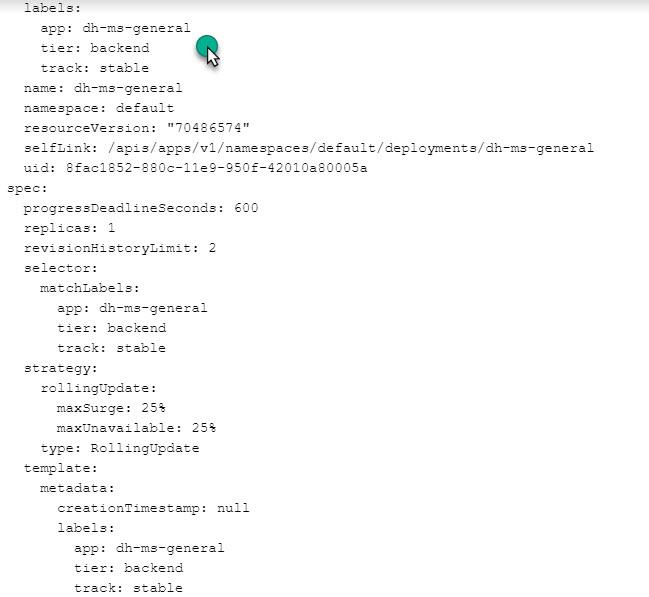
Microservices are immutable. You don’t ‘copy over’ the old one, you deploy a new version. When you deploy a microservice, you create a Kubernetes deployment YAML file that defines the Label and the version of the image.
In the above example, our Label is dh-ms-general. When a microservice Label is reused for a new container image, Kubernetes stops using the old image. But in some cases, a second Label may be used allowing both services to be running at the same time. This is controlled by the configuration of your ingresses. Our new pipeline process must incorporate these new features of our modern architecture.
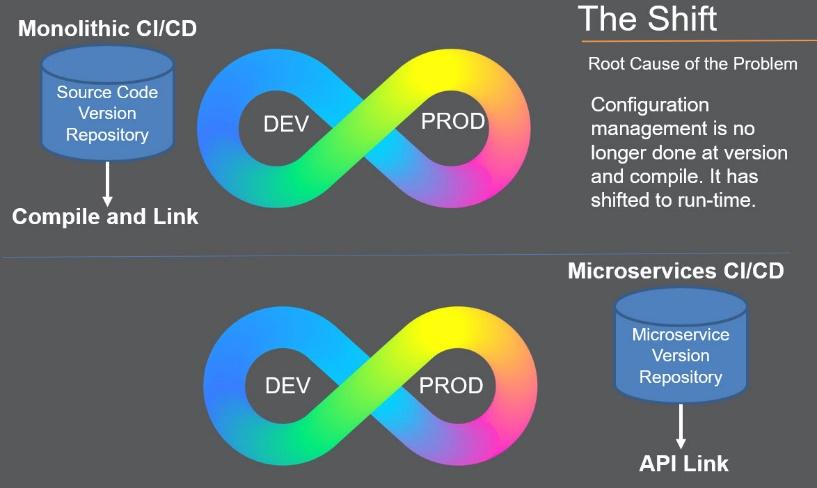
Comparing Monolithic to Microservice Pipelines
What does your life cycle pipeline look like when we manage small functions vs. a monolithic applications running in a modern architecture? Below is a comparison for each category and their potential shift for supporting a microservice pipeline.
Change Request
Monolithic:
Logging a user problem ticket, enhancement request or anomaly based on an application.
Microservices:
This process will remain relatively un-changed in a microservice pipeline. Users will continue to open tickets for bugs and enhancements. The difference will be sorting out which microservice needs the update, and which version of the microservice the ticket was opened against. Because a microservice can be used by multiple applications, dependency management and impact analysis will become more critical for helping to determine where the issue lies.
Version Control
Monolithic:
Tracking changes in source code content. Branching and merging updates allowing multiple developers to work on a single file.
Microservices:
While versioning your microservice source code will still be done, your source code will be smaller, 100-300 lines of code versus 1,000 – 3,000 lines of code. This impacts the need for branching and merging. The concept of merging ‘back to the trunk’ is more of a monolithic concept, not a microservice concept. And how often will you branch code that is a few hundred lines long?
Artifact Repository
Monolithic:
Originally built around Maven, an artifact repository provides a central location for publishing jar files, node JS Packages, Java scripts packages, docker images, python modules. At the point in time where you run your build your package manager (maven, NPM, PIP) will perform the dependency management for tracking transitive dependencies.
Microservices:
Again, these tools supported monolithic builds and solved dependency management to resolve compile/link steps. We move away from monolithic builds, but we still need to build our container and resolve our dependencies. These tools will help us build containers by determining the transitive dependencies need for the container to run.
Builds
Monolithic:
Executes a serial process for calling compilers and linkers to translate source code into binaries (Jar, War, Ear, .Exe, .dlls, docker images). Common languages that support the build logic includes Make, Ant, Maven, Meister, NPM, PIP, and Docker Build. The build calls on artifact repositories to perform dependency management based on what versions of libraries have been specified by the build script.
Microservices:
For the most part, builds will look very different in a microservice pipeline. A build of a microservice will involve creating a container image and resolving the dependencies needed for the container to run. You can think of a container image to be our new binary. This will be a relatively simple step and not involve a monolithic compile/link of an entire application. It will only involve a single microservice. Linking is done at runtime with the restful API call coded into the microservice itself.
Software Configuration Management (SCM)
Monolithic:
The build process is the central tool for performing configuration management. Developers setup their build scripts (POM files) to define what versions of external libraries they want to include in the compile/link process. The build performs configuration management by pulling code from version control based on a ‘trunk’ or ‘branch. A Software Bill of Material can be created to show all artifacts that were used to create the application.
Microservices:
Much of what we use to do for configuring our application occurred at the software ‘build.’ But ‘builds’ as we know them go away in a microservice pipeline. This is where we made very careful decisions about what versions of source code and libraries we would use to build a version of our monolithic application. For the most part, the version and build configuration shifts to runtime with microservices. While the container image has a configuration, the broader picture of the configuration happens at run-time in the cluster via the APIs.
In addition, our SCM will begin to bring in the concept of Domain Driven Design where you are managing an architecture based on the microservice ‘problem space.’ New tooling will enter the market to help with managing your Domains, your logical view of your application and to track versions of applications to versions of services. In general, SCM will become more challenging as we move away from resolving all dependencies at the compile/link step and must track more of it across the pipeline.
Continuous Integration (CI)
Monolithic:
CI is the triggered process of pulling code and libraries from version control and executing a Build based on a defined ‘quiet time.’ This process improved development by ensuring that code changes were integrated as frequently as possible to prevent broken builds, thus the term continuous integration.
Microservices:
Continuous Integration was originally adopted to keep us re-compiling and linking our code as frequently as possible in order to prevent the build from breaking. The goal was to get to a clean ’10-minute build’ or less. With microservices, you are only building a single ‘function.’ This means that an integration build is no longer needed. CI will eventually go away, but the process of managing a continuous delivery pipeline will remain important with a step that creates the container.
Code Scanning
Monolithic:
Code scanners have evolved from looking at coding techniques for memory issues and bugs to scanning for open source library usage, licenses and security problems.
Microservices:
Code scanners will continue to be important in a microservice pipeline but will shift to scanning the container image more than the source. Some will be used during the container build focusing on scanning for open source libraries and licensing while others will focus more on security issues with scanning done at runtime.
Continuous Testing
Monolithic:
Continuous testing was born out of test automation tooling. These tools allow you to perform automated test on your entire application including timings for database transactions. The goal of these tools is to improve both the quality and speed of the testing efforts driven by your CD workflow.
Microservices:
Testing will always be an important part of the life cycle process. The difference with microservices will be understanding impact and risk levels. Testers will need to know what applications depend on a version of a microservice and what level of testing should be done across applications. Test automation tools will need to understand microservice relationships and impact. Testing will grow beyond testing a single application and instead will shift to testing service configurations in a cluster.
Security
Monolithic:
Security solutions allow you to define or follow a specific set of standards. They include code scanning, container scanning and monitoring. This field has grown into the DevSecOps movement where more of the security activities are being driven by Continuous Delivery.
Microservices:
Security solutions will shift further ‘left’ adding more scanning around the creation of containers. As containers are deployed, security tools will begin to focus on vulnerabilities in the Kubernetes infrastructure as they relate to the content of the containers.
Continuous Delivery Orchestration (CD)
Monolithic:
Continuous Delivery is the evolution of continuous integration triggering ‘build jobs’ or ‘workflows’ based on a software application. It auto executes workflow processes between development, testing and production orchestrating external tools to get the job done. Continuous Delivery calls on all players in the lifecycle process to execute in the correct order and centralizes their logs.
Microservices:
Let’s start with the first and most obvious difference between a microservice pipeline and a monolithic pipeline. Because microservices are independently deployed, most organizations moving to a microservice architecture tell us they use a single pipeline workflow for each microservice. Also, most companies tell us that they start with 6-10 microservices and grow to 20-30 microservices per traditional application. This means you are going to have hundreds if not thousands of workflows. CD tools will need to include the ability to template workflows allowing a fix in a shared template to be applied to all child workflows. Managing hundreds of individual workflows is not practical. In addition, plug-ins need to be containerized and decoupled from a version of the CD tool. And finally, look for actions to be event driven, with the ability for the CD engine to listen to multiple events, run events in parallel and process thousands of microservices through the pipeline.
Continuous Deployments
Monolithic:
This is the process of moving artifacts (binaries, containers, scripts, etc.) to the physical runtime environments on a high frequency basis. In addition, deployment tools track where an artifact was deployed along with audit information (who, where, what) providing core data for value stream management. Continuous deployment is also referred to as Application Release Automation.
Microservices:
The concept of deploying an entire application will simply go away. Instead, deployments will be a mix of tracking the Kubernetes deployment YAML file with the ability to manage the application’s configuration each time a new microservice is introduced to the cluster. What will become important is the ability to track the ‘logical’ view of an application by associating which versions of the microservices make up an application. This is a big shift. Deployment tools will begin generating the Kubernetes YAML file removing it from the developer’s to-do list. Deployment tools will automate the tracking of versions of the microservice source to the container image to the cluster and associated applications to provide the required value stream reporting and management.
Conclusion
As we shift from managing monolithic applications to microservices, we will need to create a new microservice pipeline. From the need to manage hundreds of workflows in our CD pipeline, to the need for versioning microservices and their consuming application versions, much will be different. While there are changes, the core competencies we have defined in traditional CD will remain important even if it is just a simple function that we are now pushing independently across the pipeline.
About the Author
Tracy Ragan is CEO of DeployHub and serves on the Continuous Delivery Foundation Board. She is a microservice evangelist with expertise in software configuration management, builds and release. Tracy was a consultant to Wall Street firms on build and release management for 7 years prior to co-founding OpenMake Software in 1995. She was a founding member of the Eclipse organization and served on the board for 5 years. She is a recognized leader and has been published in multiple industry publications as well as presenting to audiences at industry conferences. Tracy co-founded DeployHub in 2018 to serve the microservice development community.
Forgotten AWS EC2 instances have made everyone’s pockets hurt (including Puppet!). Take it from us (relay.sh team) — if you don’t proactively clean up unused EC2 instances, cloud spending can quickly get out of control. However, it can be tedious to routinely check which EC2 instances are still in use, track down the old ones, and remove them. Luckily — we know how to automate these tasks!
Our mission is to free you to do what robots can’t.
This post walks you through de-provisioning unused EC2 instances by using AWS Lambda and CloudFormation to deploy an EC2 reaper that uses simple Tags to cut down on spending.
The AWS Reaper works by checking and enforcing tags that are set on the EC2 instances. All EC2 instances must be tagged with a lifetime or a termination_date. The termination_date defines a future date after which the EC2 instance will be terminated. Alternatively, the Reaper looks for a lifetime tag– if found, it calculates a new future date and adds that date as the termination_date tag for the EC2 instance.
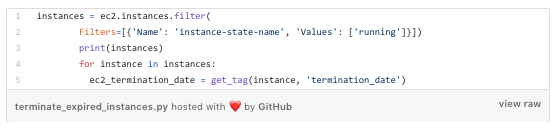
First, let’s look at the reaper.py. The main reaper logic for handling instances is in the terminate_expired_instances function which lists instances and looks up the termination date tag for each instance:
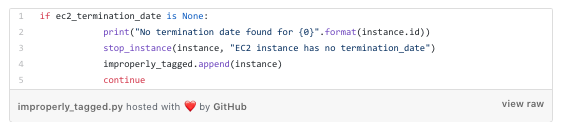
Improperly Tagged Instances
If we find an instance that doesn’t have a termination_dateor we find the tag can’t be parsed, we stop it:
This enables us to stop the b̶l̶e̶e̶d̶i̶n̶g̶ billing while we contact the instance owner to see if it should still be kept around.
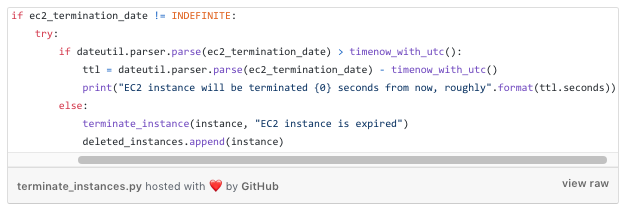
Expired Instances
For all instances we find that are expired, we destroy:
Deploying the EC2 reaper
Now, we could just run this python script against different AWS regions and we’d already be better off than doing this manually. However, we would rather not spend time babysitting scripts at all. We’re going to deploy this into AWS using CloudFormation Stacks.
Deploying the AWS reaper has two parts:
deploy_to_s3.yaml AWS CloudFormation template that places the lambda zip resources in S3 buckets in every region so that the deploy_reaper template can read them for Reaper deployment.
deploy_reaper.yaml AWS CloudFormation template that installs the reaper creates the IAM role and deploys the lambda function to perform the instance reaping.
deploy_to_s3 template
In order to use this template, you must first manually create an S3 bucket that contains the resources to copy across all regions. You will need to do this once per region; S3 resources can be read between accounts but not between regions for AWS Lambda. This only needs to be done one time for the administrative account.
Manually create an S3 bucket accessible from the administrative account. Zip up the two python reaper files, reaper.py and slack_notifier.py and place them in the bucket, naming them reaper.zip and slack_notifier.zip.
From the administrative account, create a new stack set and use the deploy_to_s3 template. An example CLI invocation would look like:
Deploy stack-set-instances for this stack set, one per region in the administrative account. Check the Amazon documentation for the most up-to-date region list. For example:
Once deployed, the EC2 Reaper will not reap anything unless the environment variable LIVEMODE is set to TRUE. It will only report what it would have done to Slack.
When the time comes to activate the Reaper, update the parameter value LIVEMODE to “TRUE”(the regex is case-insensitive).
Now you have learned how to control costs on AWS by reaping old EC2 instances. To learn more about our mission and product, sign up for our updates on relay.sh. Our mission is to free you of tedious cloud-native workflows with event-driven automation! For more content like this, please follow our medium page at https://medium.com/relay-sh.
I am so excited to engage with all of you members associated with the Continuous Delivery Foundation (CDF) as a newly appointed CDF Ambassador.
Let me introduce myself to you !
I am currently working full-time as the Global community Ambassador and Region Head of APJ & MEA region at DevOps Institute, which is the world’s fastest and largest growing DevOps professional’s association consisting of vibrant Humans of DevOps community located worldwide.
I hold expertise as an emerging best practices evangelist and in building massive global, social and online communities with the commitment to connect the Humans of DevOps and Modern IT to advance the Skills, Knowledge, Ideas & Learning (SKIL) with ease, sharing and extensive collaboration. I am a frequent Speaker at local and international conferences and also the Core organizer of Global SKILup Day and Chief Evangelist of Ambassador program by DevOps Institute. Some of my public presentations are also available on YouTube for reference. I am passionate about engaging with various community members & leaders spanned across Industries and domains worldwide.
In 2019, I traversed across the world for various speaking and organizing engagements for the community & Partners with key regions like US, Europe and executed a Asia-Pacific roadshow spanning across India, Singapore, Indonesia, Australia & New Zealand. Some of the glimpses from last year engagements while you can find more on my LinkedIn updates.
I am so excited to associate with CDF as an Ambassador for a variety of reasons. The core values of CDF with an Open-governance and vendor neutral model and providing guidance and resources to foster collaboration and eventually empowering developers, teams to produce and release high quality software is an unprecedented and fantastic initiative.
Since, I have been part of the global communities across multiple domains and regions as a member, facilitator, committee members, organizer – I am enthusiastic to contribute and support the global community of CD Foundation. As a CDF Ambassador, I would like to amplify and resonate the core values of CD Foundation to reach wider audience and networks while building an inclusive community of developers, vendors, Industry Partners, members and end users facilitating sustainable projects that are part of the broad and growing continuous delivery ecosystem.
I would love to engage with each one of you actively across platforms either in your nearby locations or at an upcoming Conferences or meetups or Online summit where I am either participating, speaking or organizing. There is so much to look forward to and so much more to share, learn and advance together as the Humans of CD Foundations. You can find me in some of the upcoming conferences or meetups below which are confirmed and also can connect with me on LinkedIn or Twitter with below details.
By Jacqueline Salinas, CDF Director of Ecosystem & Community Development
Dear CDF Members –
Please welcome the first cohort of CDF Community Ambassadors (CDF CA)! You might be wondering what exactly is a CDF Community Ambassador (CDF CA)? Well, a CA is a passionate volunteer, representative of CDF, and Meetup super host & organizer. The vision of the CA program is to help grow the network of passionate CI/CD communities and connect them through various efforts that the CD Foundation is launching in 2020. The CD Foundation sees these CA’s as the troops on the ground rallying the community together. They are stewards of CI/CD education & best practices for their local community, active open source project contributors, and leaders helping drive awareness of open source projects.
These 13 folks have stepped up and committed to helping grow awareness about the CD Foundation, as well as, help us deploy new Meetup user groups in new locations as an effort to drive more events globally. These CA’s will continue to deliver CI/CD education to their local community and most importantly help recruit new Meetup members. These volunteers are vital to the CI/CD community and to the CD Foundation! Help me give them a warm welcome to the CD Foundation community. To help you get to know our CDF Community Ambassadors better, look for their individual blogs coming in the next few weeks.
Prefer a more active role? Learn more about what it takes to become a CDF Community Ambassador. Here’s more about what the role of the CDF Community Ambassador entails:
o The Community Go-To Resource for People Interested in CDF
As a Community Ambassador, you will be an important resource to people interested in the CDF and its corresponding projects. We will provide you with training on how to best represent the CDF and provide discount codes for you to attend CDF-sponsored events.
o Help Local Users Learn More About CDF
As a Community Ambassador, you will organize and host a local CDF Users Group meetup. The CDF will provide resources to help you set up your meetup and ongoing support such as swag credits and reimbursements for costs associated with running a community event.
o Represent the Community Publicly
As a Community Ambassador, you will be a public-facing community representative. You can choose the way you are most comfortable representing CDF whether that’s through public speaking or written content such as blogs. We will work with you to find the best fit and provide you with resources to help you be successful as either a speaker, a writer, or both!
Originally posted on the Armory blog, by Rosalind Benoit
Guess what?! Our Hackathon is going fully online! “Spinnaker Gardening Days #CommunityHack” happens in one month, and we’re gearing up for an international open-source work-from-home extravaganza! Via Zoom, Slack, and Github, we’ll empower you to move the needle on continuous delivery projects. Teams will hack, newcomers will train, and champions will share Spinnaker secrets. Click here to register and get your free tickets for the hackathon, training track, lunchtime learnings, or all three.
Join other Spinnaker users and companies to learn and let your skills shine at this collaborative event. We’ll address open-source feature requests, extend the ecosystem, and have lots of fun. Thanks to our generous sponsor Salesforce, all logged-in participants will score prizes, premium swag, and lunch on us! Hack through the workday, or check out our noontime lightning talks. Visit the Spinnaker Gardening repository for the schedule and details.
The Armory Tribe celebrates the support of Salesforce and, in particular, Edgar Magana, a Spinnaker champion and Cloud Operations Architect. We recently sat down to discuss the Ops SIG, modeling and standardizing Spinnaker, and his ideas for hackathon projects. Read the full article here.
A relative newcomer to the Spinnaker community, but a veteran in matters of cloud computing, networking, and OSS projects like OpenStack, Edgar recently founded the Operations SIG (Special Interest Group). Just as he recognized that “the community needed a place to discuss how to operate Spinnaker better,” he also urges us to jump-start the Spinnaker community. He’s recommended improvements to the contributor experience, and persuaded Salesforce to sponsor this first-ever Spinnaker hackathon.
@spinnakerio I am looking for blogs and tutorials to become a developer contributor. I have found some docs in the #spinnaker web site but looking for more.
Of course, we touched on his most pressing open-source Spinnaker initiatives in our chat. Next up? Gather a team!
“We really want to come to the hackathon with goals, and to put extra motivation for folks to address them as a community,” Edgar explains their sponsorship.
From Salesforce and the Ops SIG perspective, Edgar has two features stories to focus on at the hackathon:
“Run any OSS source code scanning software against Spinnaker microservices, and you’ll find a number of vulnerabilities in the libraries that Spinnaker leverages. We’d like to minimize and solve those as much as possible.”
I’m pumped about this one because a) in many instances, this is a low-barrier-to-entry task that newer contributors can make a huge dent in, and b) every ops freak knows that fixing OSS dependencies is probably the most important security measure we touch.
“Cloud driver scalability is another key initiative in progress. The dynamic account system works, but performance can be improved drastically for those using a large system with 800-1000 Kubernetes accounts. There was a bugfix in 1.17, but it still takes lots of time for clouddriver to cache new accounts, and this means a long startup time.”
Edgar would like to see new accounts dynamically appended to the cache instead of triggering another cache of all accounts, and has been collaborating with Armory engineers on a solution. Another excellent project goal for Community Gardening!
Here on Armory’s Community team, we second Edgar’s suggestion to make Spinnaker more “beginner-friendly” and welcoming to new contributors. Our top goals for the first half of 2020 revolve around improving the contributor experience, from promoting issue triage in SIGs, to creating and organizing documentation around Spinnaker development environment, release cycle, and contribution guidelines so that newcomers know where to find answers and how to get started. Expect to see a contributor experience project from us at the hackathon!
In the meantime, the Plugin Framework for Spinnaker that Armory and Netflix are building is maturing fast. This work will make Spinnaker more welcoming to contributors in another way: it provides clear extension points in the codebase, along with an easy way to load extensions to a running Spinnaker instance. With the Spinnaker Gardening Days, we want encourage you to build extensions. Moreover, we know that many teams using Spinnaker in production have already built custom tooling around it; we’re encouraging those teams to leverage the plugin framework to quickly share their work with the OSS community (sounds like a stellar hackathon project!). We’re better together, and with a widely adopted project like Spinnaker, you can feel sure that paying it forward will reap big dividends for you and your organization. Check out the Plugin Creators Guide and Plugin Users Guide to learn more!
Calling Edgar and all other incredible Spinnaker developers: it’s time to add your fantastic Spinnaker Gardening ideas to the Project Ideas Wiki, create a slack channel for your project, and start prepping for the most exciting online event of 2020! Don’t forget to register here and reserve your ticket : )
Last year on the 12th of March 2019, the Continuous Delivery Foundation was launched at the Open Source Leadership Summit. Community leaders from Spinnaker, Jenkins, Tekton and Jenkins X came together to kick off the CDF as the new home for open source collaboration in CI/CD.
Since then we have made a lot of progress – earlier this year we produced our first annual report that showcases our efforts from our first few months. We also produced the first CD Foundation Interactive Landscape to help clarify the tools needed to adopt a fully automated CD process.
We didn’t stop there! Our CI/CD meetups are now at 25,000+ members in 67 groups spread across 30 countries! There’s probably a CI/CD meetup nearby you. Come participate!
We also have Special Interest Groups (SIGs) in Interoperability, Security, and Machine Learning (MLOps) as ways for people to participate in specific areas of expertise or interest.
And we’ve had a wide array of new members and new projects join. Membership spans a broad range of industries, international markets, and sizes of organizations. New members in the past year include Japanese Global 500 IT services provider Fujitsu, Integration Platform-as-a-Service provider Boomi, DevOps platform Cycloid, the Association of DevOps Professionals, the DevOps Institute, Global commerce leader eBay, leading global financial services firm JPMorgan Chase, and Open Source components management company Whitesource.
These new General Members bring the membership total to 33 and join Premier Members CapitalOne, CircleCI, Cloudbees, Fujitsu, Google, Huawei, IBM, jFrog, Netflix and Salesforce in working together to make continuous delivery tools and processes as accessible and reliable as possible and grow the overall ecosystem.
And just last month Screwdriver joined as our first incubation project. Screwdriver is a self-contained, pluggable service to help developers build, test, and continuously deliver software using the latest containerization technologies. Screwdriver was originally developed by Yahoo, now Verizon Media, as simplified interfacing for Jenkins. It was open sourced in 2016 and completely rebuilt to handle deployments at scale along with CI/CD goals.
Where are we headed? In our first year we have mapped out our 9 strategic objectives and our one year anniversary is a great way to round up how we are doing working towards them.
Drive Continuous Delivery Adoption – The CDF Interactive Landscape was one big initiative kicked off this year to help clarify the tools needed to adopt a fully automated CD process.
Champion Diversity & Inclusion – Initiatives in this space include diversity scholarships for our events and participation in Outreachy which have allowed us to start welcoming more voices into our communities.
Foster Community Relations – We have started soliciting priorities and working with many different communities. The Jenkins Area Meetups were contributed to CDF and expanded to CI/CD meetups and we also offer online training courses.
Grow the membership base – We are proud to have a membership of over 30 organizations which includes end user companies, vendors, start-ups, universities and institutes.
Create value for all members – We continue to listen to feedback from our individual and organization members. We held many events in 2019 including our popular mindshare cocktail hour as a way to stay close to the needs of our members.
Expand into emerging tech areas – One of the key area has been around MLOps – marrying DevOps with Machine learning through the efforts of our MLOps Special Interest Group.
We have had a lot of work done by our community. Thank you! And we have lots more fun on the way.
To keep up-to-date, sign up for our newsletter and join us in 2020 as we continue to grow and advance CI/CD in the industry!
Originally posted on the Spinnaker Community blog, by Rob Zienert, Sr Software Engineer @ Netflix
Long, long ago, in an internet that I barely remember, I wrote about monitoring Orca. I haven’t managed to take the time to write another post about a specific service — it’s a lot of work! Instead of going deep this time around, I want to paint with broader strokes: What are the key metrics we can track that help quickly answer the question, “Is Spinnaker healthy?”
Spinnaker is comprised of about a dozen open source services that may vary widely based on configuration, and as such, there’s no singular metric to rule them all. This makes the question, “Is Spinnaker healthy?” a particularly bothersome question since not all services are equally important. If Igor — the service that is responsible for monitoring CI/SCM systems — is unable to communicate with Jenkins, Spinnaker will be in a degraded state, but its core behavior is still healthy. Should Orca’s queue processing drop to zero, however, it’s time to have an elevated heart rate and quick remedy.
Service Metrics
The Service Level Indicators for our individual services can vary depending on configuration. For example, Clouddriver has cloud provider-specific metrics that should be tracked in addition to its core metrics. For the sake of this post’s length, I won’t be going into any cloud-specific metrics.
Universal Metrics
All Spinnaker services are RPC-based, and as such, the reliability of requests inbound and outbound are supremely important: If the services can’t talk to each other reliably, someone will be having a poor experience.
For each service, a controller.invocations metric is emitted, which is a PercentileTimer including the following tags:
status: The HTTP status code family, 2xx, 3xx, 4xx...
statusCode: The actual HTTP status code value, 204, 302, 429...
success: If the request is considered successful. There’s nuance here in the 4xx range, but 2xx and3xx are definitely all successful, whereas 5xx definitely are not
controller: The Spring Controller class that served this request
method: The Spring Controller method name, NOT the HTTP method
Similarly, each service also emits metrics for each RPC client that is configured via okhttp.requests. That is, Orca will have a variety of metrics for its Echo client, as well as its Clouddriver client. This metric has the following tags:
status: The HTTP status code family, 2xx, 3xx, 4xx...
statusCode: The actual HTTP status code value, 204, 302, 429...
success: If the request is considered successful
authenticated: Whether or not the request was authenticated or anonymous (if Fiat is disabled, this is always false)
requestHost: The DNS name of the client. Depending on your topology, some services may have more than one client to a particular service (like Igor to Jenkins, or Orca to Clouddriver shards).
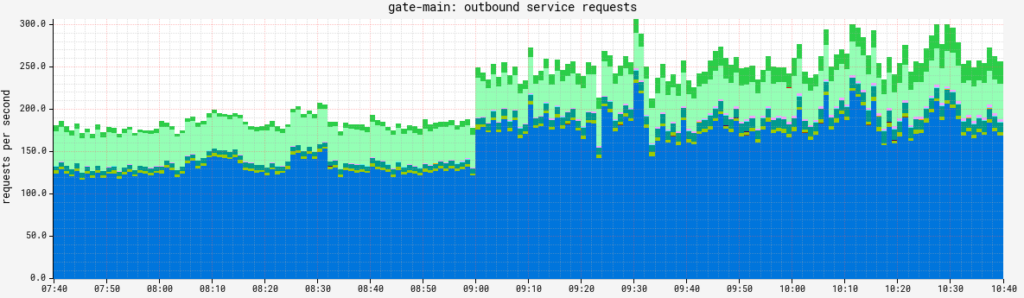
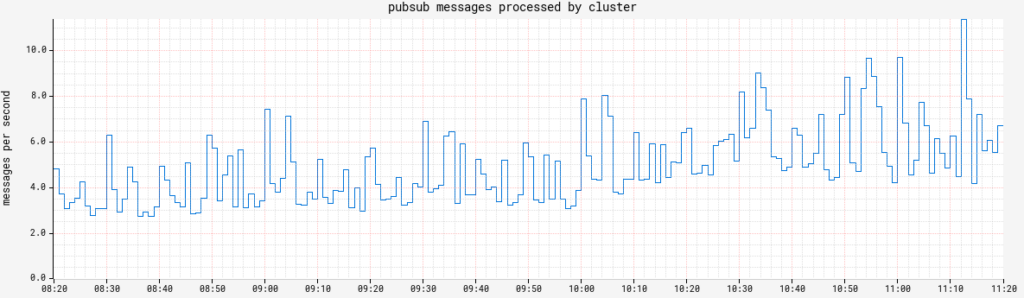
Example of our 24/7 request fanout from Gate. One interesting tidbit: The sudden increase in traffic at 9am is the increased traffic to Clouddriver (bottom) from Chaos Monkey starting its daily light mayhem!
Having SLOs — and consequentially, alerts — around failure rate (determined via the succcess tag) and latency for both inbound and outbound RPC requests is, in my mind, mandatory across all Spinnaker services.
As a real world example, the alert Netflix uses for Orca to all of its client services is:
So, for people who can’t read Atlas expressions, if we have more than 0.2 failing/unknown RPS to a specific service over 3 minutes, we’ll get an alert.
Service-specific Metrics
Most of our services have an additional metric to judge operational health, but in/out RPC monitoring will go far if you’re just starting out.
Echo echo.triggers.count tracks the number of CRON-triggered pipeline executions fired. This value should be pretty steady, so any significant deviation is an indicator of something going awry (or the addition/retirement of a customer integration). echo.pubsub.messagesProcessed is important if you have any PubSub triggers. Your mileage may vary, but Netflix can alert if any subscriptions drop to zero for more than a few minutes.
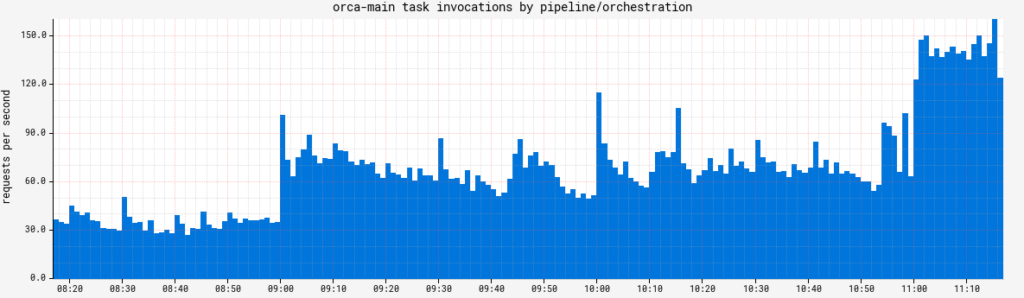
Orca task.invocations.duration tracks how long individual queue tasks take to execute. While it is a Timer, for an SLA Metric, its count is what’s important. This metric’s value can vary widely, but if it drops to zero, it means Orca isn’t processing any new work, so Spinnaker is dead in the water from a core behavior perspective.
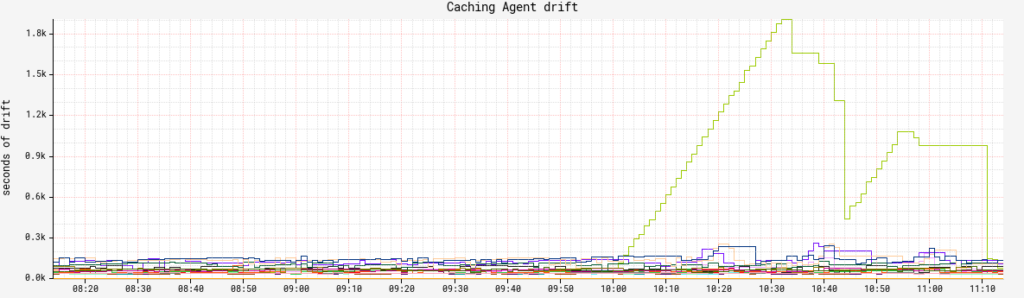
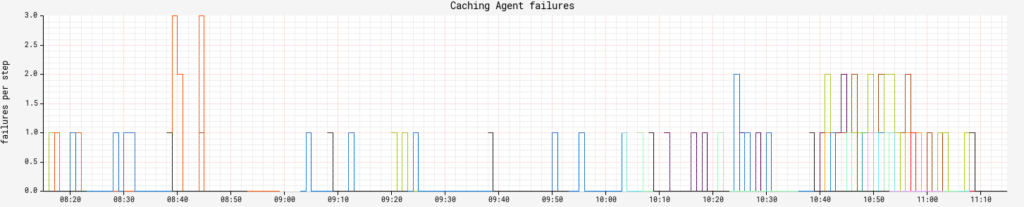
Clouddriver: Each cloud provider is going to emit its own metrics that can help determine health, but two universal ones I recommend tracking are related to its cache. cache.drift tracks cache freshness. You should group this by agent and region to be granular on exactly what cache collection is falling behind. How much lag is acceptable for your org is up to you, but don’t make it zero. executionCount tracks the number of caching agent executions and combined with status , we can track how many specific caching agents are failing at any given time.
Here, one collection for a specific AWS service in our largest region was getting stale. In this case, while AWS availability was fine for Clouddriver, Edda was having trouble refreshing.It’s OK that there are failures in agents: As stable as we like to think our cloud providers are, it’s still another software system and software will fail. Unless you see sustained failure, there’s not much to worry about here. This is often an indicator of a downstream cloud provider issue.
Igor pollingMonitor.failed tracks the failure rate of CI/SCM monitor poll cycles. Any value above 0 is a bad place to be, but is often a result of downstream service availability issues such as Jenkins going offline for maintenance. pollingMonitor.itemsOverThreshold tracks a polling monitor circuit breaker. Any value over 0 is a bad time, because it means the breaker is open for a particular monitor and it requires manual intervention.
Product SLAs at Netflix
We also track specific metrics as they pertain to some of our close internal customers. Some customers care most about latency reading our cloud cache, others have strict requirements in latency and reliability of ad-hoc pipeline executions.
In addition to tracking our own internal metrics for each customer, we also subscribe to our customers’ alerts against Spinnaker. If internal metrics don’t alert us of a problem before our customers are aware something is wrong, we at least don’t want to wait for our customers to tell us.
Continued Observability Improvements
Since Spinnaker is such a large, varied system, blog posts such as these are fine, but really are meant to get the wheels turning on what could be possible. It also highlights a problem with Spinnaker today: A lack of easily discoverable operational insights and knobs. No one should have to rely on a core contributor to distill information like this into a blog post!
There’s already been a start to improving automated service configuration property documentation, but something similar needs to be started for metrics and matching admin APIs as well. A contribution that documents metrics, their tags, purpose and related alerts would be of huge impact to the project and something I’d be happy to mentor on and/or jumpstart.
Of course, if you want to get involved in improving Spinnaker’s operational characteristics, there’s a Special Interest Group for that. We’d love to see you there!
Coming soon from Chime to OSS, a software delivery chatbot which uses Slack to deploy apps via Spinnaker
Last month I had the pleasure of chatting with Robert Keng, a Lead SRE at Chime, about a Slack-integrated ChatBot he recently built to facilitate lightweight, direct deployments for developers. Chime’s continuous delivery is based on Spinnaker, driven with signal-based GitOps. Via pipelines, merged release branches are auto-deployed from a continuous integration (CI) solution, through QA to production with no human interaction interaction.
However, it hasn’t always been this way; Chime has roots in a legacy build environment, largely for Ruby-on-Rails development. It’s based on configuration management tools such as Salt, and thus not containerized, but pointed at long-lived infrastructure. So, containerization formed an important milestone in Chime’s continuous delivery adoption. Luckily, according to Robert, its high-trust, growth minded culture and workflows have supported the evolution.
Chime’s culture also provides flexibility that highlights Spinnaker’s power to accelerate digital transformation. Robert explains that, in some instances, it makes sense for developers to deploy straight to a test environment, bypassing CI. When adding a small feature to a mobile app, for example, I might want to bypass CI wait time to deploy and experiment with behavior (raise your hand if you‘ve built an app and never done that…didn’t think so!)
Meeting Chime devs where they’re @
“We’re cutting the straight-to-prod patch fix deployments down to zero,” Robert clarifies, and he’s done it by creating a flexible system with Spinnaker that models Chime’s culture of trust. At any time, if the devs he enables would rather execute commands in Slack to deploy branches to environments of their choosing, they can. Robert has created a tool that allows them that agency, while empowering them to address complex use cases, for example, adding logic into the Slack commands to deploy dynamic environments into different Kubernetes clusters. In production, “If we need to scale customers on the Z-axis, and build multiple app versions with different backends to target different service providers” as deployment targets, with Spinnaker, Chime can. Robert points out:
“Spinnaker offers a lot of agility in that respect. It would be hard to accommodate gitOps and chatOps in the same place without it.”
In a prime example of the opportunities to solve that Spinnaker provides as a platform, Robert has created a golden path which allows Chime’s teams to iterate in a safe environment. To create it, Robert analyzed workflows as they are and designed an alternative workflow that mapped what he observed in Spinnaker. This, combined with the auto-deploy strategy, tells the story, written in pipelines, of how Chime engineers deliver software. This way, as an SRE, he can rely on automated guardrails for safety regardless of the deployment path. As Kelsey Hightower says, it “serializes the culture in tools” in a way that’s seamless, painless, and purposefully abstracted.
Because at the end of the day, it’s not about the tools. It’s about your story, which in Chime’s case, is all about changing the way people feel about banking. What products and services do you delight your customers with? What’s your story? You can tell it #withSpinnaker
One DeploymentBot, Headed for OSS Spinnaker
The tool, in a multi-service design, has a component which handles the request/response communication with Slack, a frontend that leverages Okta user groups to control who can access Spinnaker, and a Python backend which processes the request data in batches. This architecture evolved from using webhooks to, at Armory’s suggestion, using client certs for faster authentication, and from a monolith version to microservices, because of constraints encountered in the bot’s development. The top constraint: the Slack Events API’s requirement that a response from requests arising from message actions be received within 3 seconds.
This constraint presented challenges in actions like querying Vault for certificates to authenticate against Spinnaker, and even in token exchange with Slack. Breaking the chatbot into pieces allowed Robert to create a responsive, extensible service to deliver a full-featured experience for Chime devs. “It’s turned into a monster,” he grins. “I have tons of feature requests for additional functionality already” (because his devs love using it).
Next steps for Robert’s Bot include developing it against the entire Spinnaker API to leverage all features available, and adding more dynamic capability. He wants to enable devs to use the bot to deal with existing pipelines and executions, and adjust parameters and other configuration via a scripted payload directly from Slack.
Another important next step? Open-sourcing the DeploymentBot! Robert’s very busy with projects right now (read more below), but I’ll hook him up with support from Armory engineers, if needed, to help get this invention to the masses.
The Future of Site Reliability, Platforms, and DevOps Engineering
As he describes his plans for the Bot, we start talking about the myth of NoOps. I have my own words about the opportunities and fallacies of Dev + Ops, but here, Robert’s voice speaks for itself:
“My team isn’t DevOps, it’s SRE (Site Reliability Engineering). DevOps is just part of what we do. As tech stacks mature, we’re seeing less dependency on direct hardware interaction, but that doesn’t mean the management complexity goes away; it actually gets worse. Here’s an easy example: We have this awesome thing called Kubernetes. Given config maps and secrets, where is the source of truth? Ask anyone in the community, and they’ll say, ‘Umm…build it yourself!’ I know Hashicorp released a sidecar method to inject values, but none of that is complete. This is why there’s a lot of custom work in the community, and companies are building their own mutating webhook controllers, for example, which is what we’re doing. You can’t buy this stuff, because it doesn’t exist.
We have our own way of injecting Vault secrets which 100% bypasses Kubernetes stuff, because we can’t version it, and we can’t manage it from any source or truth, as it’s scattered across 1000 namespaces. It’s impossible to manage in one place. So in our environment, we put everything in Vault, whether it’s configuration, or secrets. That gives us a common interface to code against. In V1, we’re using init containers, which is exactly what Hashicorp’s sidecar does. In V2, depending on the environment, we’ll grab values from different Vault clusters, since storing production and non-production values in the same place is just, suicide. You’ll get a huge ban hammer from your security team, and no-one wants that.
So we’re building, and we’re operating it at the same time. And are developers ever going to touch these [tools]? No! There are a lot of these instances in Kubernetes where things just don’t exist, so what do you do?Same thing for, EC2, and ECS even. Then, moving into Knative, and Lambas, and serverless computing and functions, it’s even worse. It’s a free-for-all. We’re designing our own framework.
The next thing we’re looking at is building plugins that will plug in our code, and use Spinnaker to deploy it [on that infra]. I heard Armory is working on something similar for deploying Lambdas, and I’m desperately waiting, because it’s going to make my life easier. Functions in general are kind of useless. The ecosystem around them is more important; you’ve got to think about API gateways, API management, queues, load balancers, etc. How do I wrap that into a sane framework where we can consistently build, integrate, test, and deploy? I don’t want to use 10 different ways to do the same thing. I’d rather just have everything work in Spinnaker.”
Then when we start talking about making that happen. I tell Robert about the Community Gardening Days I’m planning for Spinnaker this Spring (keep your eyes peeled! Announcement forthcoming on Spinnaker.io and social), and he gets psyched about Chime’s involvement. Music to my ears!
Look out for more articles from me on the Spinnaker developer and contributor experience. I’ll shine a light on the way Open Source Heroes like Robert are getting into the ecosystem as they enable the delivery of software products and services. Hang on, the latest industrial revolution (where software truly changes the freaking world for the better!) is just taking off.
Please share this on Twitter, LinkedIn, and HackerNews and give Robert some glory : )
A problem the Spinnaker community currently ISN’T having ^^
I’d like to start sharing one IC’s experience (mine : ) dropping anchor into the Spinnaker ecosystem. I found the community last year before joining the tribe at Armory, while doing research for another continuous delivery product built on Tekton. First step: join Spinnaker slack, and behold the community live, with active SIG channels, newcomers, and operators constantly pinging to discuss what they encounter in the platform.
What’s the next step? Personally, I began creeping on Spinnaker.io, joined the Docs SIG which maintains the site, and began to engage by commenting on and submitting web-dev PRs in the site’s repository to get the ball rolling. Next up: get my full Spinnaker dev environment set up, and document that process for y’all!
If you’re an end-user, your path may look different: you may have used Spinnaker to deploy an application, and encountered a usability issue or found something not quite right from your perspective. In this case, reaching out on Slack in the #general or relevant SIG channel, or filing an issue in the spinnaker/spinnaker repository describing your observation is the next step. As a final note to end-users, having spoken to Andy Glover and a few TOC members about this at some length, I can say on good authority:Why end-users and new contributors should submit issues to the project
Why end-users and new contributors should submit issues to the project
Push past your fear in filing an issue! At this stage in its growth, the “too many issues” problem doesn’t exist. We’ll skip across that bridge when we come to it. Now, we need your feedback to make the most mature and production-ready continuous delivery platform the BEST platform on the planet. Don’t be shy!
Operators will also follow their own path to begin contributing. Perhaps you’ve found a great growth opportunity for the codebase as you’ve hacked through workflows. Maybe you’ve developed a rockin’ integration to solve for interoperability at your organization, and you know it may benefit others in the community. Or, that small tweak made to your organization’s Spinnaker instance has improved usability, but hasn’t been addressed in the community.
YES, your time is precious, but I urge you, don’t wait! Sharing your contributions will help the ecosystem, and it will also help you. It puts you on the map. It adds gravitas to your resume. It exposes you to peer recognition, and provides networking with some teeth, as your community footprint will speak for itself. Better yet, if you start a fix or conversation, others in the community can advise, or build on what you started, helping you solve faster.
If you’d like to add a feature to Spinnaker, that should start as a discussion, so file an issue in the spinnaker/spinnaker repository describing the purpose and proposed implementation, or start the discussion at a SIG meeting. Got something smaller-scale, like a bug fix? The Submitting A Patch page on spinnaker.io provides guidance. Integrating another service, or building an extension? Check out the Plugin Users Guide, as utilizing the new plugin framework allows you to maintain plugin code in a separate repository and avoid the requirement of loading extensions at Spinnaker runtime.
If that’s a bit overwhelming for now, don’t despair. Getting started is the first step. Noticed something confusing in the docs, or have a suggestion for spinnaker.io? Have ideas on what kinds of Contributor Experience materials would help you move forward? Please ping us in #SIG-Documentation or file an issue in spinnaker/spinnaker.github.io!
That’s all for today, but stay tuned for more N8B Diaries as I work to guide Spinnaker operators in contributing their inventions, and set up my own environment. High-five your imposter syndrome and become a *real* Spinnaker contributor with me!