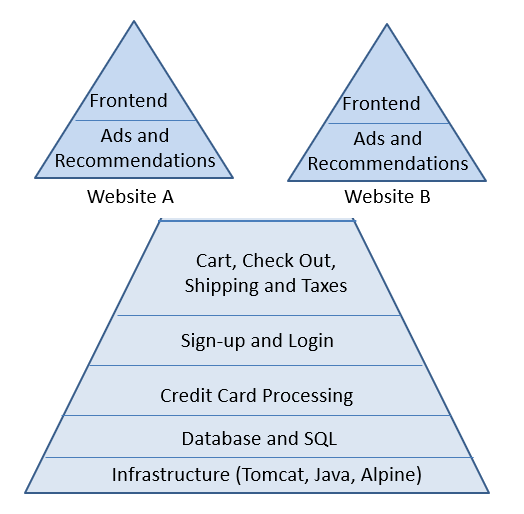
It is possible to deliver software faster without compromising reliability and agility — but only through a shared and measured DevOps practice with a particular focus on Continuous Delivery.
At the end of September, I wrote a blog called “We Need to Stop Using the Term CI/CD,” not to destroy something that you’re used to, but because I believe…
I volunteered to co-moderate our Tekton Birds of a Feather session with Dan Lorenc (of Tekton fame) – and after it finished I honestly thought to myself... “that was quite…
The CDF has been busy spreading its wings in 2020, welcoming new members and growing its community, who finally get to comes together for the first-ever CDCon (Oct. 7-8)