

A look at the structure of Jenkins' documentation, its ongoing improvements, and contributing to Jenkins documentation.
Read More
Come along and I'll share what we're up to and what I personally think the Tekton community does well to give its consumers and developers confidence in building something better…
Read More
Interested in using code quality analysis tools and want to run secure builds using virtual machines or containers?
Read More
The terms “master” and “slave” are being replaced. What terminology will we use from now on? Find out.
Read More
Check out the great progress that has been made in Jenkins documentation
Read More
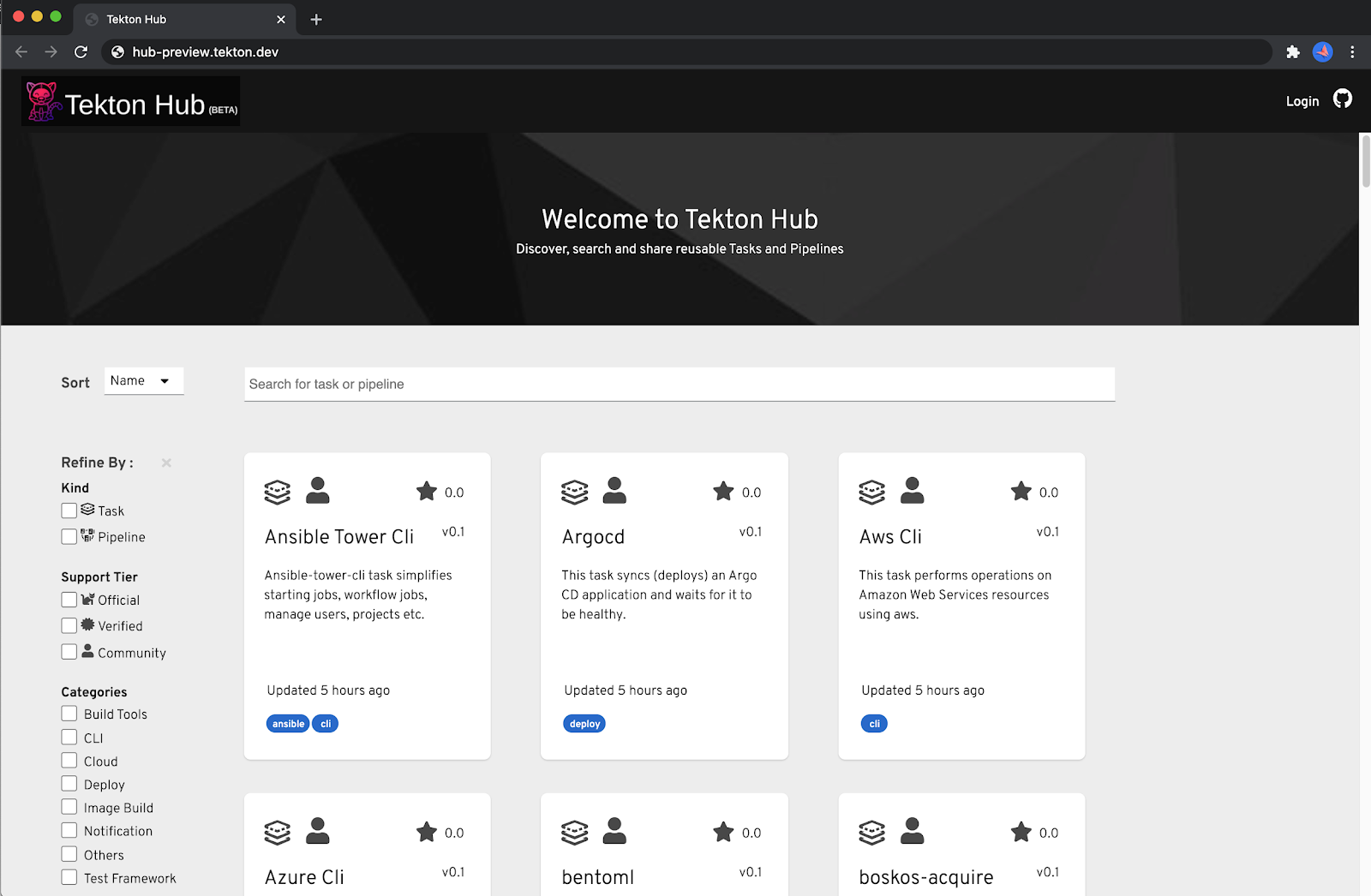
Tekton Hub provides a central hub for searching and sharing Tekton resources across many distributed Tekton catalogs hosted by various organizations and teams.
Read More
Jenkins recently announced the public community-driven roadmap.
Read More
One of the areas in which Jenkins is showing its age however is in the UI. That's why it's getting a makeover.
Read More
The people asked for and delivered the Jenkins Dark Theme!
Read More