

Contibuted by Zhongkai Liu, Software Dev Engineer II & Palash Agrawal, Principal Software Dev Engineer | originally posted on Verizon Media (not a CDF Member)

The term “migration” denotes any changes made to the database, including but not limited to inserting or deleting tables, populating data into, or removing entries from the database. Every project with a database requires regular schema updates and data migrations. Having a reliable and automated process to apply changes to databases reduces the possibility of manual error, the amount of time required, and additional communication between teams.
Prior DB Migration Process
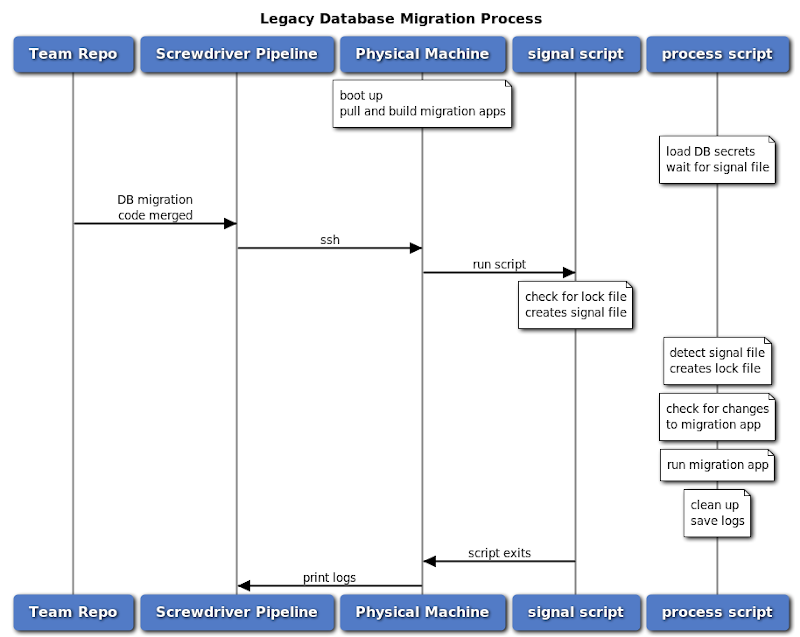
Here at Yahoo Sports, we had an existing database migration process that ran on a single physical machine. A custom locking mechanism managed by a set of shell scripts ran in the background to ensure that only one database migration ran at a time. New database migrations were checked into the project’s git repository as versioned .sql (patch) files and run through our Screwdriver (open source continuous delivery platform) pipeline. The corresponding build resulting from the merge triggered a lengthy process that ran a Flyway-based Java application to carry out the migrations from those patch files.
There were some limitations with this process:
- Multiple database migrations cannot happen in parallel, one blocks another
- Machine is idle when there is no database migration scheduled
- Locking mechanism is complex and error-prone to maintain
- Database migration app was managed by different teams and fetched and compiled for each migration
Improving the DB migration process
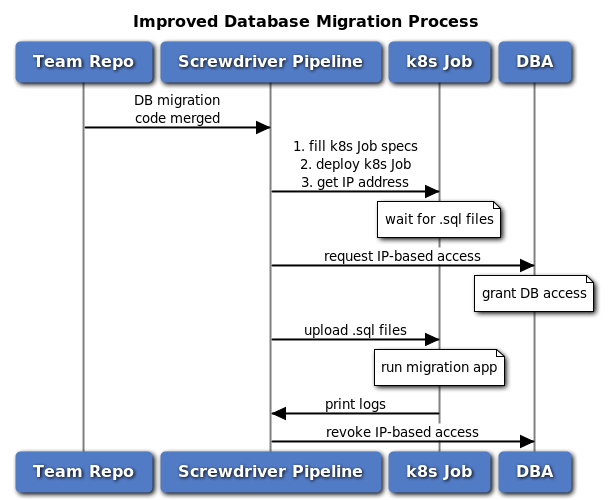
Our open source continuous delivery platform, Screwdriver, provides a mechanism to define code snippets and steps that can be shared and reused, called templates. By building a Screwdriver template for the new database migration process, teams that need to adapt to this process only need to add and configure this template in their pipeline configurations without making other code changes. Teams can add as many DB migration jobs to their pipeline as they wish, for different components or environments. We wanted to avoid making major changes to the existing flow for adding new database migrations by Sports engineers. Therefore, even in the new process, adding new migrations is still the same as before: check-in versioned .sql files into the project repository.
We improved our database migration process by moving the migrations from the physical machine to Kubernetes (k8s) as Jobs, and created a stateless Docker container that runs a Java migration application. This container can be used by multiple teams to run their database migration k8s Job. At runtime, the database configurations are passed into the container as environment variables, such as the database host and port, database credential key (explained below), migrations files, and feature flags. All of these configurations are non-sensitive. The versioned .sql files are packed and uploaded to the k8s Job container for each migration.
Athenz is an open source platform for X.509 certificate-based service authentication and fine-grained access control. It is integrated with k8s and provides unique identities to each Pod created within k8s. Our internal secret-key management service uses Athenz to manage the access to database credentials. The database migration k8s Job container fetches the database credentials from this service by providing its own certificates and the database credential key, which ensures that the database credentials are safe and secure and cannot be accessed by other jobs or systems.
Additionally, we provide a feature by default to dynamically grant database access for only the duration of each database migration. When a database migration Job starts, there is an automated procedure to add its Pod IP address to the DB ACL for granting temporary access. When the migration job completes, the same procedure revokes the database access.
As a result of this new process, we have improved auditability as each migration begins with code reviews from application owners and we are leveraging Screwdriver, Athenz, and k8s audit capability to build an audit trail of all the changes to prevent malicious and unintentional attempts to alter the database.
Results
The new database migration process requires little change on the Screwdriver pipelines and it barely alters our engineers’ workflow for maintaining database migrations. It took less than a week on average for teams to switch from running migrations on physical machines to running them on k8s. The Yahoo Sports engineering team now uses this new process for all of their database migration jobs. The new process is more efficient and maintainable.
We recently upgraded the databases to a newer version and only had to update the corresponding libraries in the database migration Docker image. No action was necessary from the teams that were already using this process.
In summary, we improved our database migration process by moving away from the centralized machine and running the migrations on k8s Jobs. This change keeps all database migrations isolated and independent from each other and allows migrations to run concurrently. We built a Screwdriver template which made it easy for new teams to adapt to this process without writing new code. We further protected the migration process by dynamically granting IP-based database access.
Acknowledgments
Special thanks to Trey Raymond from the DBA team and Rajesh Gopalakrishna Pillai from the IaaS org.
Authors
Zhongkai and Palash are engineers from the Yahoo Sports Infrastructure team. Their team is part of the Verizon Media PE group and they strive to maintain a healthy and up-to-date infrastructure for running sports apps and promoting best practices for security, testing, and reliability.