

Contributed by: Dan Lorenc
CDF Newsletter – July 2020 Article
Subscribe to the Newsletter
Buckle up. This post is going to take you on a journey we’ve all been on before – installing some open-source software, but with an adversarial mindset. Let’s start by taking a look at how a user might install the popular Python library, requests, today.
The installation page tells users to run pipenv install requests, which will install the library from the PyPI package index. Digging in there, we can see that the latest release has been uploaded as a .tar.gz file of the raw source code, as well a pre-built .whl file:
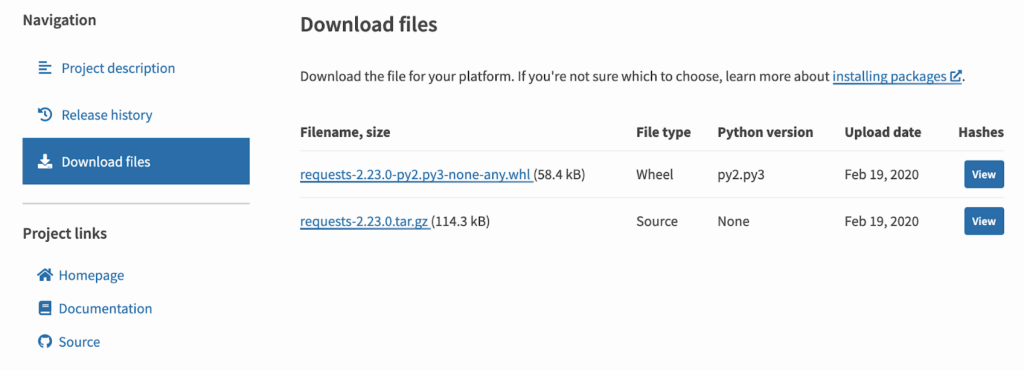
If we want to find out where this source code came from, we can follow the “Source” Project link right over to the GitHub repository for requests. This published package version (2.23.0) helpfully corresponds directly to a release tag in the repository, so we can assume that the requests-2.23.0.tar.gz file on PyPI is a snapshot of the repository at this commit.
Let’s check.
I’ll start by cloning the repository, and exporting that version as a git archive.
$ git clone git@github.com:psf/requests.git $ cd requests $ git checkout v2.23.0 $ git archive v2.23.0 --format=tar --prefix=requests-git/ -o requests.tar $ tar -xf requests.tar
Now I’ll download and extract the released version from PyPI:
$ curl -LO https://files.pythonhosted.org/packages/f5/4f/280162d4bd4d8aad241a21aecff7a6e46891b905a4341e7ab549ebaf7915/requests-2.23.0.tar.gz $ tar -xf requests-2.23.0.tar.gz
Finally, I can compare these:
$ diff requests-2.23.0 requests-git/ Only in requests-git/: .coveragerc Only in requests-git/: .github Only in requests-git/: .gitignore Only in requests-git/: .travis.yml Only in requests-git/: AUTHORS.rst Only in requests-git/: Makefile Only in requests-2.23.0: PKG-INFO Only in requests-git/: _appveyor Only in requests-git/: appveyor.yml Only in requests-git/: docs Only in requests-git/: ext Common subdirectories: requests-2.23.0/requests and requests-git/requests Only in requests-2.23.0: requests.egg-info diff requests-2.23.0/setup.cfg requests-git/setup.cfg 6,10d5 < < [egg_info] < tag_build = < tag_date = 0 < Common subdirectories: requests-2.23.0/tests and requests-git/tests Only in requests-git/: tox.ini
Oops! They’re not actually identical, but they seem close enough. The git repo contains a few extra boilerplate files that got stripped out before publication to PyPI. The meat of the library (the requests subfolder) is identical. Great! (Note: we can only make this comparison because Python is an interpreted language. It would be **much** more complicated with a compiled language.)
If I’m interested in seeing exactly what happens to transform the raw git repo to a publishable artifact on PyPI, I can do a bit of software archaeology. Opening up the Makefile, we can see that there’s a “publish” target:

This installs another tool (twine), runs a command to package this up into a distributable artifact, uses twine to upload this, then cleans up after itself. Putting an adversarial hat on for a minute, there are a few potential problems here:
- I’m now trusting the twine library, which is installed and executed as part of the release process. Twine has a chance to inject or modify the requests code before it is uploaded. If I don’t check the git repo against the published artifacts before using them, I would miss this.
- I’m trusting the request maintainers to faithfully and securely execute these commands each time. In this case, I’m sure they’re all wonderful, well-meaning individuals, but what if they get tricked or their environment gets compromised?
I’m not trying to pick on the requests library or maintainers here—this library is in far better shape than many others. For another example, check out the Kubernetes project; the core repository (github.com/kubernetes/kubernetes) contains the code for dozens of independently versioned, releasable artifacts in a handful of different formats (container images, multi-platform Go binaries, archives of YAML files). Verifiably tracing any/all of these artifacts back to the source code and build environment used to produce them is an exercise left to the reader.
A Better Way
If I don’t want to trust the maintainers to build and publish artifacts, I always have the option to clone the git repository and build them myself. But this isn’t always easy (or possible!), and I think we can do better than that.
Imagine if the requests maintainers used an automated system to publish their artifacts. Maintainers could simply tag a release in their git repository, and have the system take over from there. This system could execute their build and publish steps in a known, trusted environment, and publish the resulting artifacts to PyPI on behalf of the developers. This system could store information about the exact inputs and tools it used along the way, and make that information available publicly.
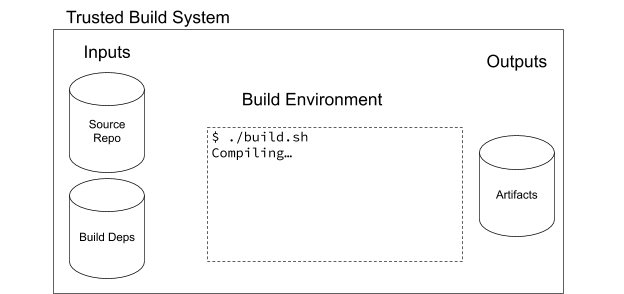
Finally, it could package up all of this metadata into a cryptographically signed payload and publish it alongside the package for the world to examine, in some kind of tamper-proof store. This would guarantee that the package I’m using was produced using the defined steps, with no possibility for injecting or modifying the code along the way.

As a user of this library, I would no longer have to trust the maintainers to securely build, package and release their artifacts. I could instead trust the operators of this automated build system. And if I didn’t or couldn’t trust any build system operators, I could always audit the build system code or even choose to run it myself.
It’s unlikely that there will be a single build system everyone in the world trusts, but it will be a lot easier to establish trust in a few systems operated and protected by experts than to rely on the security of every open-source maintainer’s personal laptop.
Just like our existing certificate authority infrastructure, build systems could be operated by anyone interested. Organizations could configure their own root trust policies, and opt to rebuild things in their own environments or other environments they trust. When compromises and incidents do occur, we would be able to easily verify exactly which artifacts were affected, and quickly rebuild them in secure environments.
What Next?
Build systems like this already exist! They’re called CI systems and have been around for decades. What we’re missing is a standard way for these systems to attest to the builds they run, to communicate this data to users, for well-meaning groups to audit and monitor these, and easy ways for organizations to stand up systems that produce these attestations.
We’re just getting started on solving this problem in the CDF! The TektonCD project has recently started an effort to produce trustable artifact metadata in a variety of formats, called Tekton Chains. To learn more or get involved, reach out on the Tekton Slack or GitHub repositories.