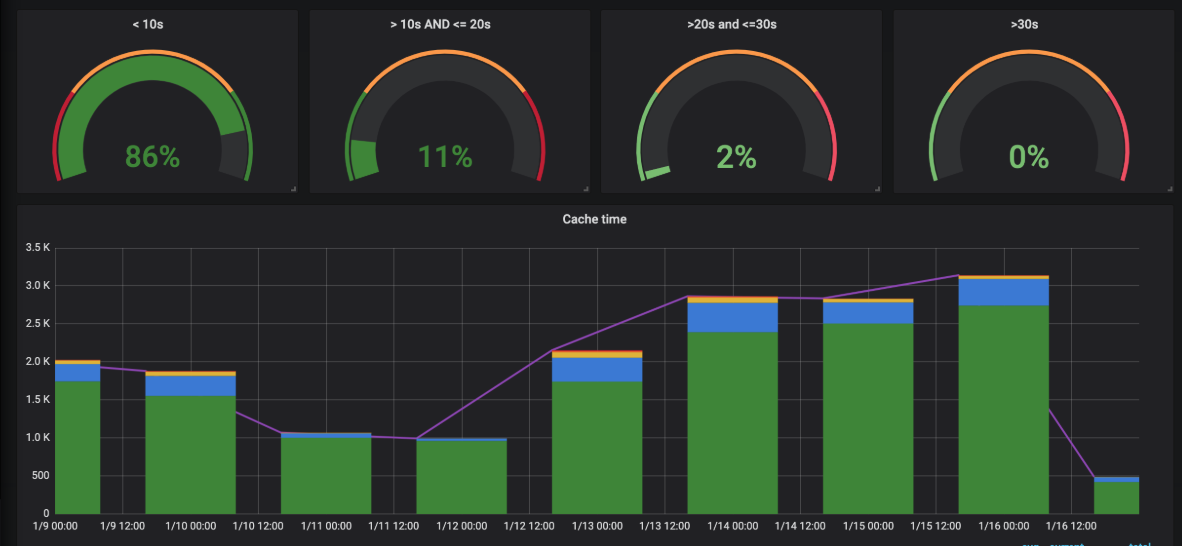
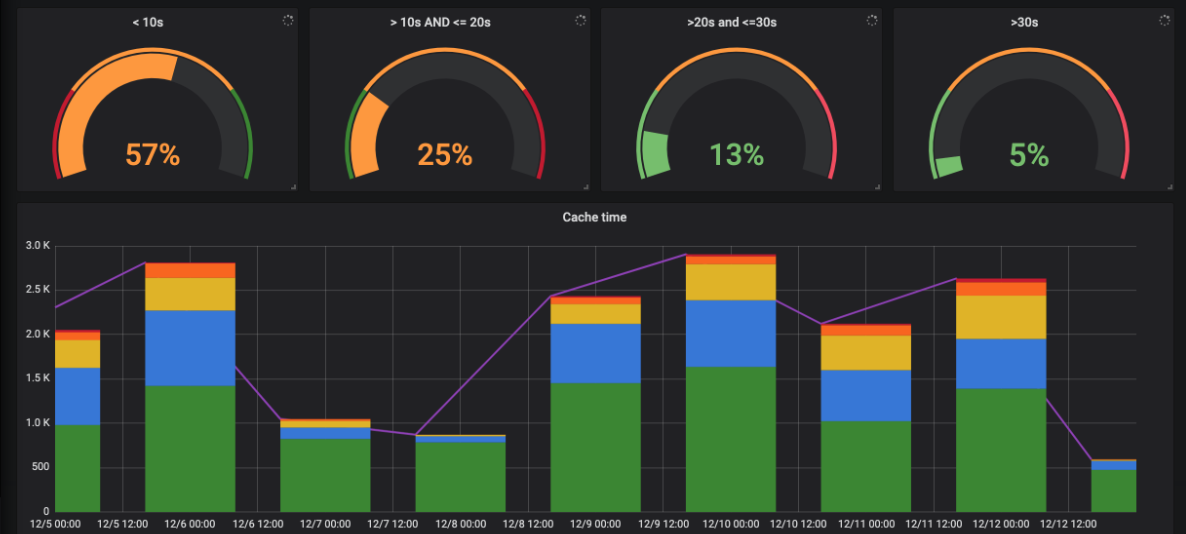
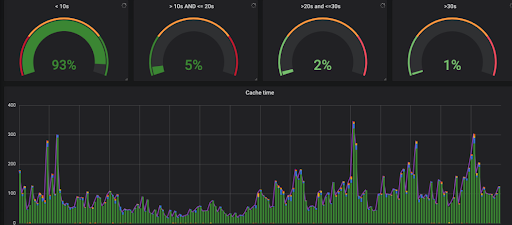
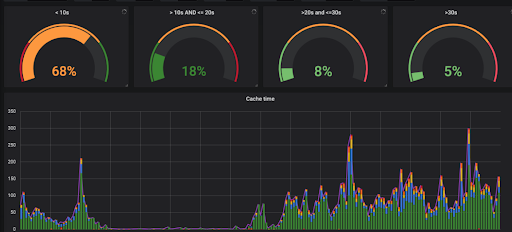
Screwdriver now has the ability to cache and restore files and directories from your builds to either s3 or disk-based storage. Rest all features related to the cache feature remains the same, only a new storage option is added. Please DO NOT USE this cache feature to store any SENSITIVE data or information.
The graph below is our Internal Screwdriver instance build-cache comparison between disk-based strategy vs aws s3.
Build cache – get cache – (disk strategy)
Build cache – get cache – (s3)
Build cache – set cache – (disk strategy)
Build cache – set cache – (s3)
Why disk-based strategy?
Based on the cache analysis, 1. The majority of time was spent pushing data from build to s3, 2. At times the cache push fails if the cache size is big (ex: >1gb). So, simplified the storage part by using a disk cache strategy and using filer/storage mount as a disk option. Each cluster will have its own filer/storage disk mount.
NOTE: When a cluster becomes unavailable and if the requested cache is not available in the new cluster, the cache will be rebuilt once as part of the build.
Cache Size:
Max size limit per cache is configurable by Cluster admins.
Retention policy:
Cluster admins are responsible to enforce retention policy.
Cluster Admins:
Screwdriver cluster-admin has the ability to specify the cache storage strategy along with other options like compression, md5 check, cache max limit in MB
Screwdriver is an open-source build automation platform designed for Continuous Delivery. It is built (and used) by Yahoo. Don’t hesitate to reach out if you have questions or would like to contribute: http://docs.screwdriver.cd/about/support.
The Spinnaker community has grown significantly after launching as an open source project in 2015. The project maintainers increasingly look for ways to help the community better understand how Spinnaker is used, and to help contributors prioritize future improvements.
Today, feature development is guided by industry experts, community discussions, Special Interest Groups (SIGs), and events like the recently held Spinnaker Summit. In August 2019, the community published an RFC, which proposed the tooling that will enable everyone to make data-driven decisions based on product usage across all platforms. We encourage Spinnaker users to continue providing feedback, and to review and comment on the RFC.
Following on from this RFC, the Spinnaker 1.18 release includes an initial implementation of statistics collection capabilities that are used to collect generic deployment and usage information from Spinnaker installations around the world. Before going into the details, here are some important facts to know:
No personally identifying information (PII) is collected or logged.
All stats collection code is open source and can be found in the Spinnaker stats, Echo, and Kork repos found on GitHub.
Users can disable statistics collection at any time through a single Halyard command.
Community members that want to work with the underlying dataset and/or dashboard reports can request and receive full access.
This feature exists in the Spinnaker 1.18 release,but is disabled by default while we finalize testing of the backend and fine-tune report dashboards. The feature will be enabled by default in the Spinnaker 1.19 release (scheduled for March 2020).
All data will be stored in a Google BigQuery database, and report dashboards will be publicly available from the Community Stats page. Community members can request access to the collection data.
Data collected as part of this effort allows the entire community to better monitor the growth of Spinnaker, understand how Spinnaker is used “in the wild”, and prioritize feature development across a large community of Spinnaker contributors. Thank you for supporting Spinnaker and for your help in continuing to make Spinnaker better!
Tekton Pipelines has shifted into beta, meaning the open source CD project is now looking for more contributors and testers.
Tekton Pipeline is the core component of the Tekton project, which is overseen by the Continuous Delivery Foundation, and is pitched to “configure and run continuous integration/continuous delivery (CI/CD) pipelines within a Kubernetes cluster.” It originated in Knative Build.
The project team said the beta means “most Tekton Pipelines CRDs (Custom Resource Definition) are now at beta level. This means overall beta level stability can be relied on.” However, other components, including Tekton Triggers, Dashboard, Pipelines CLI and more, “are still alpha and may continue to evolve from release to release”.
The team overseeing the development of the open source Tekton Pipelines under the auspices of the Continuous Delivery (CD) Foundation announced today the project is now in beta.
Christie Wilson, Tekton Project Lead and a software engineer at Google, said Tekton Pipelines are not necessarily a tool most DevOps teams will interact with directly. Rather they provide a foundation on which DevOps platforms can be built that will make it easier for DevOps teams to construct workflows spanning multiple continuous integration/continuous delivery (CI/CD) platforms.
As such, Tekton Pipelines should play a critical role in not just fostering interoperability but also alleviating concerns about become locked into a specific CI/CD platform.
Tekton Pipelines, the major component in an open-source project for CI/CD (continuous integration and continuous delivery) on Kubernetes, has reached the milestone of beta status.
Tekton was originally Knative Build, what was then one of three major components in the Knative project, the others being serving and eventing. In June 2019, Knative Build was deprecated in favour of Tekton Pipelines. A Tekton pipeline runs tasks, where each task consists of steps running on a container in a Kubernetes pod.
Tekton Pipelines, the core component of the Tekton project, is moving to beta status with the release of v0.11.0 this week. Tekton is an open source project creating a cloud-native framework you can use to configure and run continuous integration and continuous delivery (CI/CD) pipelines within a Kubernetes cluster.
Tekton development began as Knative Build before becoming a founding project of the CD Foundation under the Linux Foundation last year.
The Tekton project follows the Kubernetes deprecation policies. With Tekton Pipelines upgrading to beta, most Tekton Pipelines CRDs (Custom Resource Definition) are now at beta level. This means overall beta level stability can be relied on. Please note, Tekton Triggers, Tekton Dashboard, Tekton Pipelines CLI and other components are still alpha and may continue to evolve from release to release.
Tekton encourages all Tekton projects and users to migrate their integrations to the new apiVersion. Users of Tekton can see the migration guide on how to migrate from v1alpha1 to v1beta1.
Now is a great time to contribute. There are many areas where you can jump in. For example, the Tekton Task Catalog allows you to share and reuse the components that make up your Pipeline. You can set a Cluster scope, and make tasks available to all users in a namespace, or you can set a Namespace scope, and make it usable only within a specific namespace.
Continuous Delivery (CD) and Runbook Automation are standard means to deploy, operate and manage software artifacts across the software life cycle. Based on our analysis of many delivery pipeline implementations, we have seen that on average seven or more tools are included in these processes, e.g., version control, build management, issue tracking, testing, monitoring, deployment automation, artifact management, incident management, or team communication. Most often, these tools are “glued together” using custom, ad-hoc integrations in order to form a full end-to-end workflow. Unfortunately, these custom ad-hoc tool integrations also exist in Runbook Automation processes.
Processes usually integrate multiple tools and exist in multiple permutations
Problem: Point-to-Point Integrations are Hard to Scale and Maintain
Not only is this approach error-prone but maintenance and troubleshooting of these integrations in all its permutations is time-intensive too. There are several factors that prevent organizations from scaling this across multiple teams:
Number of tools: Although the great availability of different tools always allows having the appropriate tool in place, the numberof required integrations explodes.
Tight coupling: The tool integrations are usually implemented within the pipeline, which results in a tight coupling between the pipeline and the tool.
Copy-paste pipeline programming: A common approach we are frequently seeing is that a pipeline with a working tool integration is often used as a starting point for new pipelines. If now the API of a used tool changes, all pipelines have to catch up to stay compatible and to prevent vulnerabilities.
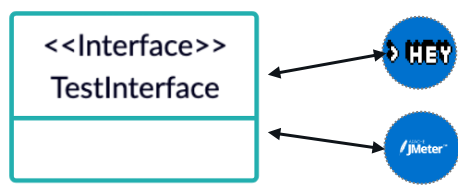
Let’s imagine an organization with hundreds of copy-paste pipelines, which all contain a hard-coded piece of code for triggering Hey load tests. Now this organization would like to switch from Hey to JMeter. Therefore, they would have to change all their pipelines. This is clearly not efficient!
In order to solve these challenges, we propose introducing interoperability interfaces, which allow abstract tooling in CD and Runbook Automation processes. These interfaces should trigger operations in a tool-agnostic way.
For example, a test interface could abstract different testing tools. This interface can then be used within a pipeline to trigger a test without knowing which tool is executing the actual test in the background.
Interface abstracts the actual tooling
These interoperability interfaces are important and this is confirmed by the fact that the Continuous Delivery Foundation has implemented a dedicated working group on Interoperability, as well as the open-source project Eiffel, which provides an event-based protocol enabling a technology-agnostic communication especially for Continuous Integration tasks.
Use Events as Interoperability Interfaces
By implementing these interoperability interfaces, we define a standardized set of events. These events are based on CloudEvents and allow us to describe event data in a common way.
The first goal of our standardization efforts is to define a common set of CD and runbook automation operations. We identified the following common operations (please let us know if we are missing important operations!):
Operations in CD processes: deployment, test, evaluation, release, rollback
Operations in Runbook Automation processes: problem analysis, execution of the remediation action, evaluation, and escalation/resolution notification
For each of these operations, an interface is required, which abstracts the tooling executing the operation. When using events, each interface can be modeled as a dedicated event type.
The second goal is to standardize the data within the event, which is needed by the tools in order to trigger the respective operation. For example, a deployment tool would need the information of the artifact to be deployed in the event. Therefore, the event can either contain the required resources (e.g. a Helm chart for k8s) or a URI to these resources.
We already defined a first set of events https://github.com/keptn/spec, which is specifically designed for Keptn — an open-source project implementing a control plane for continuous delivery and automated operations. We know that these events are currently too tailored for Keptn and single tools. So, please
Let us Work Together on Standardizing Interoperability Interfaces
In order to work on a standardized set of events, we would like to ask you to join us in Keptn Slack.
We can use the #keptn-spec channel in order to work on standardizing interoperability interfaces, which eventually are directly interpreted by tools and will make custom tool integrations obsolete!
Originally posted on the Armory blog, by Rosalind Benoit
“Let Google’s CloudBuild handle building, testing, and pushing the artifact to your repository. #WithSpinnaker, you can go as fast as you want, whenever you’re ready.”
Calling all infrastructure nerds, SREs, platforms engineers, and the like: if you’ve never seen Kelsey Hightower speak in person, add it to your bucket list. Last week, he gave a talk at Portland’s first Spinnaker meetup, hosted at New Relic by the amazing PDX DevOps GroundUp. I cackled and cried at the world’s most poignant ‘Ops standup’ routine. Of course, he thrilled the Armory tribe with his praise of Spinnaker’s “decoupling of high level primitives,” and I can share some key benefits that Kelsey highlighted:
Even with many different build systems, you can consolidate deployments #withSpinnaker. Each can notify Spinnaker to pick up new artifacts as they are ready.
Spinnaker’s application-centric approach helps achieve continuous delivery buy-in. It gives application owners the control they crave, within automated guardrails that serialize your software delivery culture.
Building manual judgements into heavy deployment automation is a “holy grail” for some. #WithSpinnaker, we can end the fallacy of “just check in code and everything goes to prod.” We can codify the steps in between as part of the pipeline.
Spinnaker uses the perfect integration point. It removes the brittleness of scripting out the transition between a ‘ready-to-rock’ artifact and an application running in production.
Kelsey’s words have profound impact. He did give some practical advice, like “Don’t run Spinnaker on the same cluster you’re deploying to,” and of course, keep separate build and deploy target environments. But the way Kelsey talked about culture struck a chord. We called the meetup, “Serializing culture into continuous delivery,” and in his story, Kelsey explained that culture is what you do: the actions you take as you work; your steps in approaching problems.
Yes, please!
I’m reminded of working on a team struggling with an “agile transformation” through a series of long, circular discussions. I urged my team, “Scrum is just something that you do!” You go to standups, and do demos. You get better at pointing work over time. The ceremonies matter because you adapt by doing the work.
Kelsey says his doing approach starts with raising his hand and saying, “I would like to own that particular problem,” and then figuring it out as he goes. Really owning a problem requires jumping in to achieve a deep understanding of it. It’s living it, and sharing with others who have lived it. We can BE our culture by learning processes hands-on, digging into the business reasons behind constraints, and using that knowledge to take ownership. Hiding behind culture talk doesn’t cut it, since you have to do it before you can change it.
“The return on investment is totally worth it”
Another important way of doing: recognizing when you don’t know how to do it and need some help. Powerful open source projects like Kubernetes and Spinnaker can become incredibly complicated to implement in a way that faithfully serializes your culture. Responsible ownership means getting the help you need to execute.
I love how Kelsey juxtaposed the theatrics and hero mythology behind change management and outage “war rooms” with the stark truth of the business needs behind our vital services. As Kelsey shared his Ops origins story, I recalled my own – the rocket launch music that played in my head the first time I successfully restarted the java process for an LMS I held the pager for, contrasted with the sick feeling I got when reading the complaining tweets from university students who relied on the system and had their costly education disrupted by the outage. I knew the vast majority of our students worked full time and paid their own way, and that many had families to juggle as I do. This was the real story of our work. It drove home the importance of continuous improvement, and meant that our slow-moving software delivery culture frustrated the heck out of me.
Kelsey’s LOL simulation of the Word doc deployment guide at his first “real” job. Got a deployment horror story about a Word-copied command with an auto-replaced en-dash on a flag not triggered until after database modification scripts had already run? I do!
So what do you do if you’re Kelsey? You become an expert at serializing a company’s decisions around software delivery and telling them, as a quietly functioning story, with the best-in-class open source and Google tooling of the moment. He tells the story of his first automation journey: “So I started to serialize culture,” he says, when most of the IT department left him to fend for himself over the winter holidays. Without trying to refactor applications, he set to work codifying the software delivery practices he had come to understand through Ops. He automated processes, using tools his team felt comfortable with.
He said, “We never walked around talking about all of our automation tools,” and that’s not a secrecy move, it’s his awareness of cognitive dissonance and cognitive overload. Because he had created a system based on application owners expectations, their comfort zone, he didn’t need to talk about it! It just worked (better and more efficiently over time, of course), and fulfilled the business case. Like Agile, this approach limits the scope of what one has to wrap their brain around to be excellent. Like Spinnaker, it empowers developers to focus on what they do best.
Instead of talking about the transformation you need, start by starting. Then change will begin.
By Forest Jing, Jenkins Ambassador and JAM organizer in China
On February 29, 2020, the first CI/CD Meetup in China was successfully held online. The atmosphere of this online live streaming event was hot and welcomed. There were more than 5,000 people and 27,000 pageviews! Several CI/CD experts have shared the practices about CI, CD, and DevOps. Although affected by the COVID-19, but it could not stop everyone’s passion of learning.
CI/CD Meetup is a global community event hosted by the Continuous Delivery Foundation (CDF), which aims to build a CI/CD ecosystem and promote CI/CD related practices and open source projects. The CI/CD Meetup in China is co-organized by Jenkins Ambassador Shi Xuefeng, Lei Tao, and Jing Yun who are also organizers of Jenkins Area Meetup in China. And DevOps Times community and GreatOps community are co-organizer of the event. We hope we could introduce CI/CD to more Chinese IT companies to improve their IT performance.
More than 5,000 people online and 27,000 pageviews Everyone is enthusiastic to leave messages and interact
Everyone likes the content and is curious to ask the lecturers: “As a programmer, why do you all have so luxuriant hairs?”
Details from the live broadcast content
Topic 1· CI/CD Practice of Large Mobile App
Shi Xuefeng, Engineering Efficiency Director of JD.COM,Jenkins Ambassador and Core author of DevOps Capability Maturity Model
First of all, Shi Xuefeng brought the wonderful topic of “Large Mobile App CI/CD.”
In the mobile era, mobile applications have become the main battlefield of business. In this activity, Xuefeng shared how is the CI/CD of a super large app is designed and implemented.
Topic 2· The implementation and practice of Agile && DevOps at CITIC Bank
Shi Lilong,Senior Expert, Software Development Center, CITIC Bank
Subsequently, Shi Lilong, a senior expert at the software development center of CITIC Bank, brought a wonderful sharing of “the implementation and practice of Agile and DevOps in CITIC Bank”.
Mr. Shi Lilong shared the overall promotion of CITIC Bank in Agile and DevOps, and the end-to-end tool chain of CITIC Bank.
Topic 3: How do large-scale financial and Internet companies conduct product library management?
Wang Qing,JFrog Chief Architect in China
Wang Qing, Chief Architect of JFrog China, brought a wonderful sharing of “How do large financial and Internet companies manage product libraries?”
Due to the large number of R & D personnel and large types of products delivered by large financial companies and Internet companies, the application dependent libraries and product libraries have become complicated and difficult to manage. After the implementation of many enterprise-level user product libraries, the advanced functions of the work-in-progress library solve the above problems and open up the second pulse of continuous delivery.
Topic 4: Watch out! 10 obstacles in DevOps Transformation
Shi Jingfeng, Senior DevOps expert in GreatOPS Community
Mr. Shi Jingfeng brought a wonderful sharing of “Watch out! 10 obstacles in DevOps Transformation.”
During the these days, many companies have started to work from home. Various obstacles appeared on the first day of WFH. The conference system was unstable, VPN connection was not available, remote desktops were queued, and the phone was busy. The implementation of DevOps seemed make all of these very easy . Jingfeng thinks that DevOps is like a journey, there are both beautiful attractions and obstacles. It is difficult to save yourself by not paying attention to the obstacles? How these pain points are addressed based on the DevOps Capability Maturity Model.
DevOps Capability Maturity Model
Experts Q&A
The last topic is a CI/CD expert question and answer part. All experts will answer the questions raised.
Experts solve problems for everyone online
Finally, the last group photo of the experts, the CI/CD Meetup online salon was successfully held.
This event was co-sponsored by the CDF, DevOps Times community, and GreatOPS community. Thanks to the strong support of JFrog and Tencent Cloud Community.
The last story of the first CI/CD Meetup in China.
Jenkins Ambassadors
Shi Xuefeng (BC), Lei Tao and Forest Jing are the Jenkins Ambassador who are always organizing JAM in China. We all visited DevOps World Lisbon. At the event, we met Kohsuke Kawaguchi and Alyssa Tong. So we discussed to introduce CI/CD Meetup into China. It is a fantastic event.
Chinese DevOps Experts with KK in DevOps World Lisbon