Find out why 2020 is the year of Spinnaker at https://Spinnaker.Live on June 18th at 9:00am PDT. Learn how enterprises accelerate with open source Spinnaker at this Linux Foundation virtual conference co-hosted by the CD Foundation and Armory.
“The CD Foundation seeks to improve the world’s capacity to deliver software with security and speed,” said Rosalind Benoit, Director of Community at Armory, and Chair of the CD Foundation Outreach Committee. “Spinnaker.Live speaks to everyone invested in software delivery collaboration and automation. Open source is powered by connections, and this event is to meet, connect, and hear great stories. Please bring your energy and ideas to this incredible global community!”
Spinnaker is a free and open source continuous delivery software platform developed by Netflix and Google to create tailor-made, collaborative continuous delivery pipelines. With unique multi-cloud building blocks, it integrates all the tools, approvals, and infrastructure needed to automate an enterprise software delivery lifecycle.
Spinnaker is housed under the CD Foundation umbrella at the Linux Foundation. It is a Founding Project of the CD Foundation.
Continued Growth in 2020
Spinnaker is continuing to grow in 2020, boasting more contributors and more Pull Requests than ever before.
Key statistics for 2020
Q1 2020 was the first quarter since Spinnaker was open sourced that the project had at least 2 new contributors each week
Of the 1,183 contributors to Spinnaker in the last year, 464, or 40%, contributed in Q1 2020
Merged Pull Requests have skyrocketed in 2020. These are the code and documentation contributions that the project accepts and incorporates.
Average since open sourced: 399/month
Average in the last 12 months: 605/month
Previous high was 656 (March 2019, 1.6x the average since being open sourced)
February 674 (1.7x avg)
March 891 (2.2x avg)
April 962 (2.5x avg)
May 755 (1.9x avg)
Notable Amazon Support
Spinnaker has been implemented widely with well known companies like Adobe, AirBnb, Autodesk, Comcast, Salesforce, SAP, and many more using Spinnaker to handle the software delivery life cycle. Of note, Amazon Web Service (AWS) has dramatically increased contributions to Spinnaker in 2020.
Up-to-date statistics are available on Devstats. They show a strong spike coming into 2020 in AWS contributions, with pull requests in recent months more than tripling 2019’s monthly highs. Amazon has stated publicly that they are backing Spinnaker due to strong enterprise customer demand.
AWS will be prominently represented at Spinnaker.Live with a keynote, breakout session, panel, and use case talks from AWS experts and companies who deploy software to AWS. Don’t miss it!
Originally posted on the Spinnaker Community blog, by Rob Zienert, Sr Software Engineer @ Netflix
Long, long ago, in an internet that I barely remember, I wrote about monitoring Orca. I haven’t managed to take the time to write another post about a specific service — it’s a lot of work! Instead of going deep this time around, I want to paint with broader strokes: What are the key metrics we can track that help quickly answer the question, “Is Spinnaker healthy?”
Spinnaker is comprised of about a dozen open source services that may vary widely based on configuration, and as such, there’s no singular metric to rule them all. This makes the question, “Is Spinnaker healthy?” a particularly bothersome question since not all services are equally important. If Igor — the service that is responsible for monitoring CI/SCM systems — is unable to communicate with Jenkins, Spinnaker will be in a degraded state, but its core behavior is still healthy. Should Orca’s queue processing drop to zero, however, it’s time to have an elevated heart rate and quick remedy.
Service Metrics
The Service Level Indicators for our individual services can vary depending on configuration. For example, Clouddriver has cloud provider-specific metrics that should be tracked in addition to its core metrics. For the sake of this post’s length, I won’t be going into any cloud-specific metrics.
Universal Metrics
All Spinnaker services are RPC-based, and as such, the reliability of requests inbound and outbound are supremely important: If the services can’t talk to each other reliably, someone will be having a poor experience.
For each service, a controller.invocations metric is emitted, which is a PercentileTimer including the following tags:
status: The HTTP status code family, 2xx, 3xx, 4xx...
statusCode: The actual HTTP status code value, 204, 302, 429...
success: If the request is considered successful. There’s nuance here in the 4xx range, but 2xx and3xx are definitely all successful, whereas 5xx definitely are not
controller: The Spring Controller class that served this request
method: The Spring Controller method name, NOT the HTTP method
Similarly, each service also emits metrics for each RPC client that is configured via okhttp.requests. That is, Orca will have a variety of metrics for its Echo client, as well as its Clouddriver client. This metric has the following tags:
status: The HTTP status code family, 2xx, 3xx, 4xx...
statusCode: The actual HTTP status code value, 204, 302, 429...
success: If the request is considered successful
authenticated: Whether or not the request was authenticated or anonymous (if Fiat is disabled, this is always false)
requestHost: The DNS name of the client. Depending on your topology, some services may have more than one client to a particular service (like Igor to Jenkins, or Orca to Clouddriver shards).
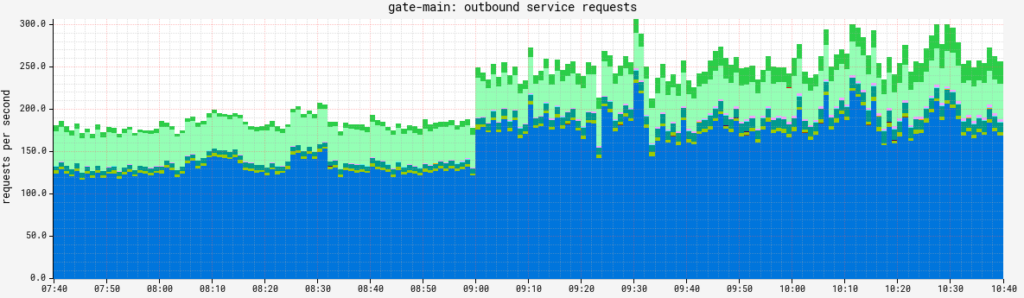
Example of our 24/7 request fanout from Gate. One interesting tidbit: The sudden increase in traffic at 9am is the increased traffic to Clouddriver (bottom) from Chaos Monkey starting its daily light mayhem!
Having SLOs — and consequentially, alerts — around failure rate (determined via the succcess tag) and latency for both inbound and outbound RPC requests is, in my mind, mandatory across all Spinnaker services.
As a real world example, the alert Netflix uses for Orca to all of its client services is:
So, for people who can’t read Atlas expressions, if we have more than 0.2 failing/unknown RPS to a specific service over 3 minutes, we’ll get an alert.
Service-specific Metrics
Most of our services have an additional metric to judge operational health, but in/out RPC monitoring will go far if you’re just starting out.
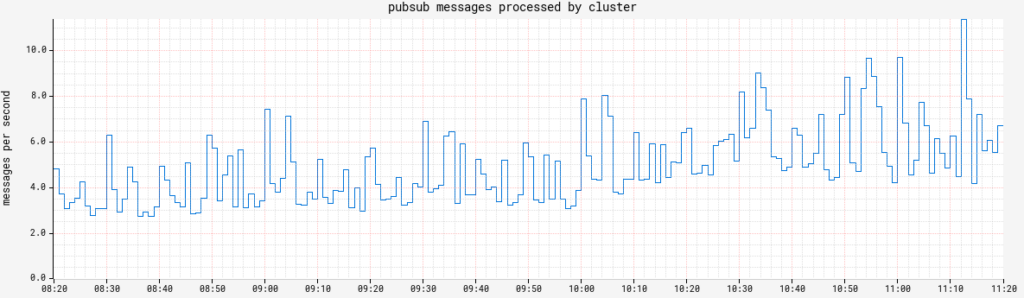
Echo echo.triggers.count tracks the number of CRON-triggered pipeline executions fired. This value should be pretty steady, so any significant deviation is an indicator of something going awry (or the addition/retirement of a customer integration). echo.pubsub.messagesProcessed is important if you have any PubSub triggers. Your mileage may vary, but Netflix can alert if any subscriptions drop to zero for more than a few minutes.
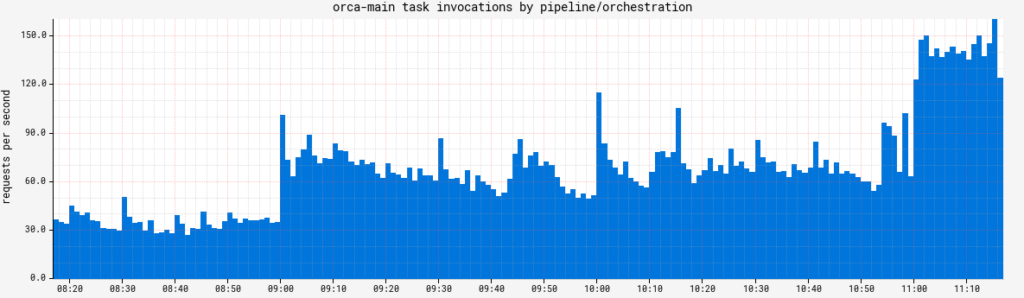
Orca task.invocations.duration tracks how long individual queue tasks take to execute. While it is a Timer, for an SLA Metric, its count is what’s important. This metric’s value can vary widely, but if it drops to zero, it means Orca isn’t processing any new work, so Spinnaker is dead in the water from a core behavior perspective.
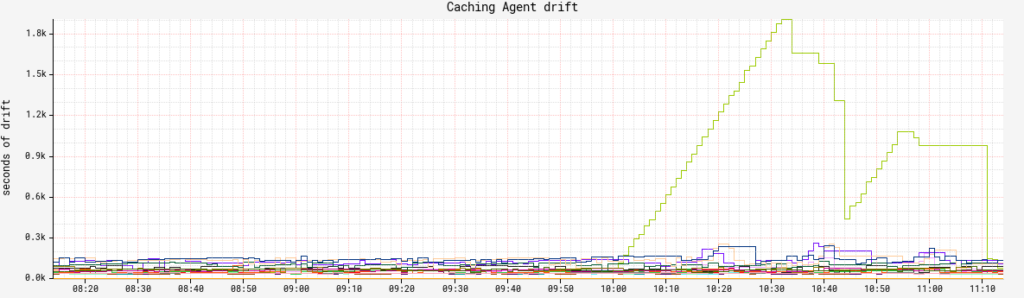
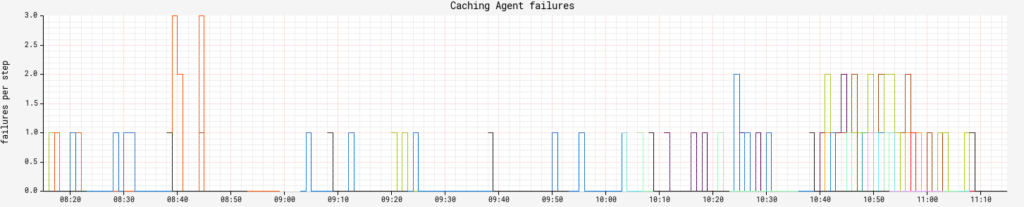
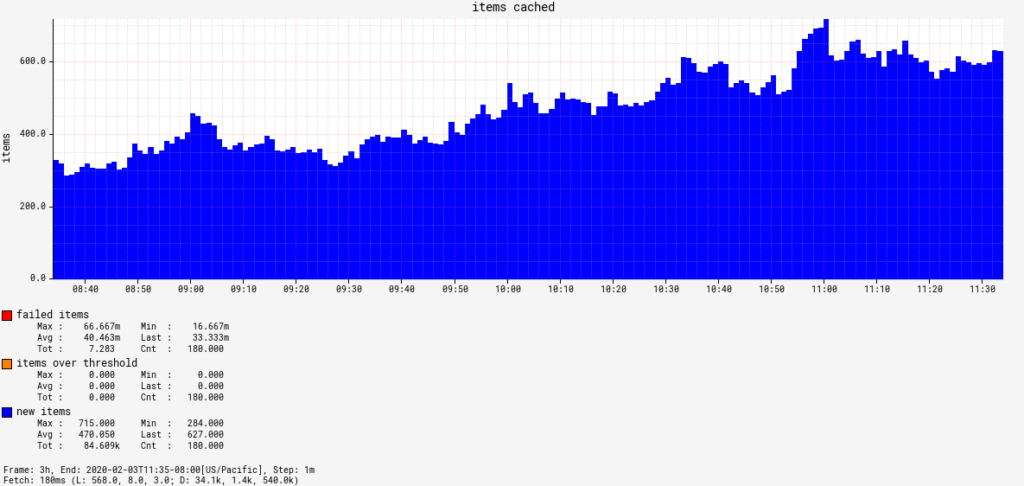
Clouddriver: Each cloud provider is going to emit its own metrics that can help determine health, but two universal ones I recommend tracking are related to its cache. cache.drift tracks cache freshness. You should group this by agent and region to be granular on exactly what cache collection is falling behind. How much lag is acceptable for your org is up to you, but don’t make it zero. executionCount tracks the number of caching agent executions and combined with status , we can track how many specific caching agents are failing at any given time.
Here, one collection for a specific AWS service in our largest region was getting stale. In this case, while AWS availability was fine for Clouddriver, Edda was having trouble refreshing.It’s OK that there are failures in agents: As stable as we like to think our cloud providers are, it’s still another software system and software will fail. Unless you see sustained failure, there’s not much to worry about here. This is often an indicator of a downstream cloud provider issue.
Igor pollingMonitor.failed tracks the failure rate of CI/SCM monitor poll cycles. Any value above 0 is a bad place to be, but is often a result of downstream service availability issues such as Jenkins going offline for maintenance. pollingMonitor.itemsOverThreshold tracks a polling monitor circuit breaker. Any value over 0 is a bad time, because it means the breaker is open for a particular monitor and it requires manual intervention.
Product SLAs at Netflix
We also track specific metrics as they pertain to some of our close internal customers. Some customers care most about latency reading our cloud cache, others have strict requirements in latency and reliability of ad-hoc pipeline executions.
In addition to tracking our own internal metrics for each customer, we also subscribe to our customers’ alerts against Spinnaker. If internal metrics don’t alert us of a problem before our customers are aware something is wrong, we at least don’t want to wait for our customers to tell us.
Continued Observability Improvements
Since Spinnaker is such a large, varied system, blog posts such as these are fine, but really are meant to get the wheels turning on what could be possible. It also highlights a problem with Spinnaker today: A lack of easily discoverable operational insights and knobs. No one should have to rely on a core contributor to distill information like this into a blog post!
There’s already been a start to improving automated service configuration property documentation, but something similar needs to be started for metrics and matching admin APIs as well. A contribution that documents metrics, their tags, purpose and related alerts would be of huge impact to the project and something I’d be happy to mentor on and/or jumpstart.
Of course, if you want to get involved in improving Spinnaker’s operational characteristics, there’s a Special Interest Group for that. We’d love to see you there!
Since releasing Spinnaker to the open source community in 2015, the platform has flourished with the addition of new cloud providers, triggers, pipeline stages, and much more. A myriad new features, improvements, and innovations have been added by an ever growing, actively engaged community. Each new innovation has been a step towards an even better Continuous Delivery platform that facilitates rapid, reliable, safe delivery of flexible assets to pluggable deployment targets.
Over the last year, Netflix has improved overall management of Spinnaker by enhancing community engagement and transparency. At the Spinnaker Summit in 2018, we announced that we had adopted a formalized project governance plan with Google. Moreover, we also realized that we’ll need to share the responsibility of Spinnaker’s direction as well as yield a level of long-term strategic influence over the project so as to maintain a healthy, engaged community. This means enabling more parties outside of Netflix and Google to have a say in the direction and implementation of Spinnaker.
A strong, healthy, committed community benefits everyone; however, open source projects rarely reach this critical mass. It’s clear Spinnaker has reached this special stage in its evolution; accordingly, we are thrilled to announce two exciting developments.
First, Netflix and Google are jointly donating Spinnaker to the newly created Continuous Delivery Foundation (or CDF), which is part of the Linux Foundation. The CDF is a neutral organization that will grow and sustain an open continuous delivery ecosystem, much like the Cloud Native Computing Foundation (or CNCF) has done for the cloud native computing ecosystem. The initial set of projects to be donated to the CDF are Jenkins, Jenkins X, Spinnaker, and Tekton. Second, Netflix is joining as a founding member of the CDF. Continuous Delivery powers innovation at Netflix and working with other leading practitioners to promote Continuous Delivery through specifications is an exciting opportunity to join forces and bring the benefits of rapid, reliable, and safe delivery to an even larger community.
Spinnaker’s success is in large part due to the amazing community of companies and people that use it and contribute to it. Donating Spinnaker to the CDF will strengthen this community. This move will encourage contributions and investments from additional companies who are undoubtedly waiting on the sidelines. Opening the doors to new companies increases the innovations we’ll see in Spinnaker, which benefits everyone.
Donating Spinnaker to the CDF doesn’t change Netflix’s commitment to Spinnaker, and what’s more, current users of Spinnaker are unaffected by this change. Spinnaker’s previously defined governance policy remains in place. Overtime, new stakeholders will emerge and play a larger, more formal role in shaping Spinnaker’s future. The prospects of an even healthier and more engaged community focused on Spinnaker and the manifold benefits of Continuous Delivery is tremendously exciting and we’re looking forward to seeing it continue to flourish.