

The terms “master” and “slave” are being replaced. What terminology will we use from now on? Find out.
Read More
A step-by-step tutorial to set up your first drone installation and build
Read More
The Pipeline as YAML plugin was created to make it simple for users who are new to Jenkins Pipeline and might not be familiar with its DSL.
Read More
Check out the great progress that has been made in Jenkins documentation
Read More
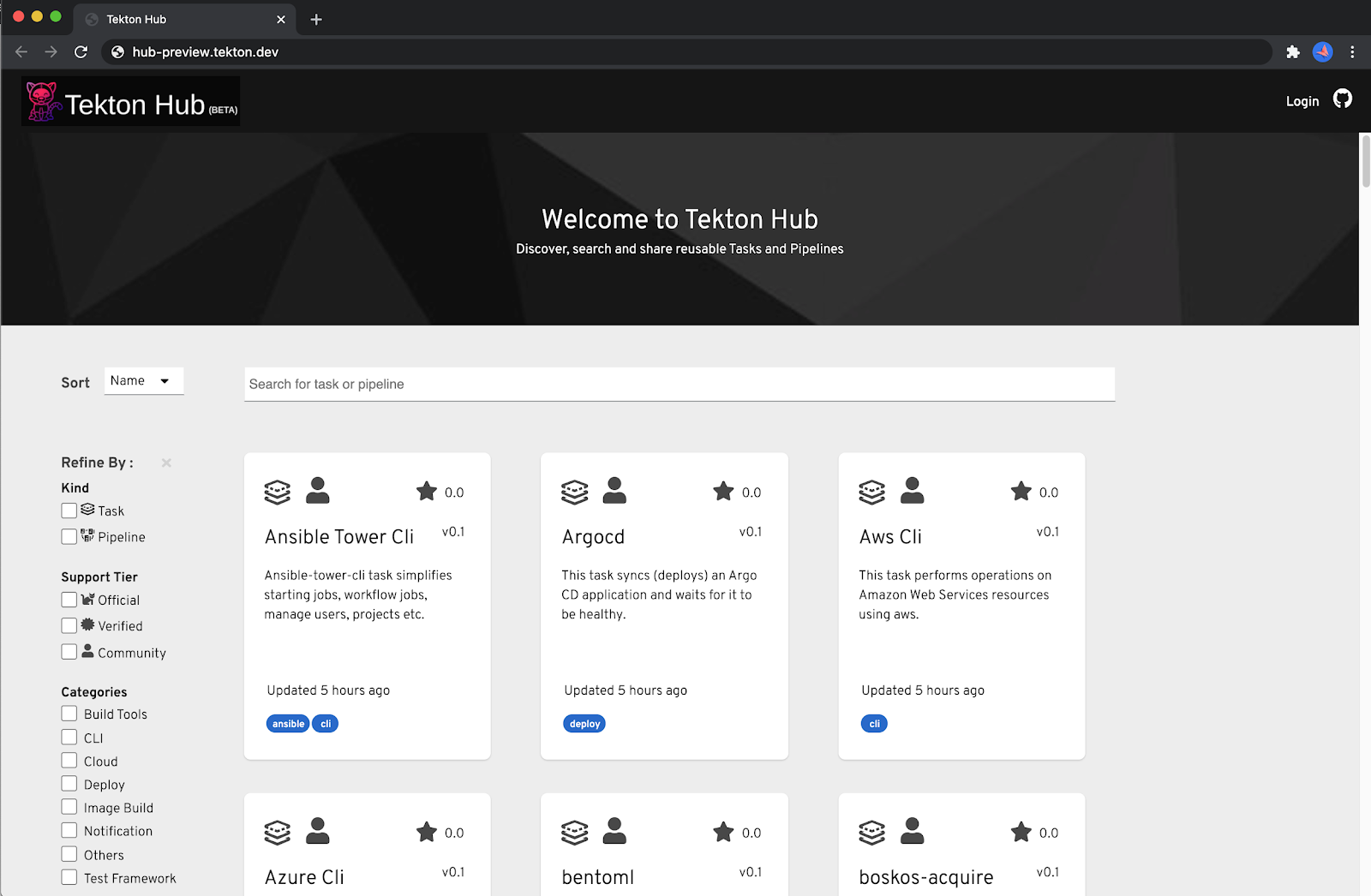
Tekton Hub provides a central hub for searching and sharing Tekton resources across many distributed Tekton catalogs hosted by various organizations and teams.
Read More
Jenkins Templating Engine. How does it work?
Read More
Jenkins is the first Continuous Delivery Foundation project to graduate.
Read More