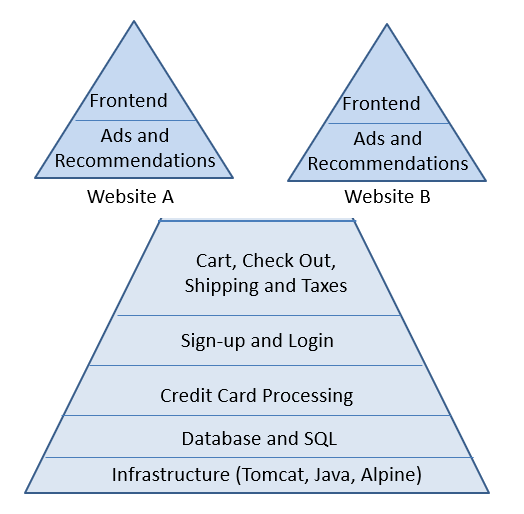
CI, CD/D and DevOps methodologies are crucial to ensuring relevance, profitability, and fast innovation. However, the domain's lack of interoperability and common standards make this challenging. What are those challenges…
It is possible to deliver software faster without compromising reliability and agility — but only through a shared and measured DevOps practice with a particular focus on Continuous Delivery.
At the end of September, I wrote a blog called “We Need to Stop Using the Term CI/CD,” not to destroy something that you’re used to, but because I believe…