

Contributed by Dan Lorenc | originally posted on medium.com
This post accompanies a talk I just gave at the 2021 Open Source Summit, called Zero Trust Supply Chain Security. The slides are available here.
Background
Let’s say you’re walking down the sidewalk outside of your office, and you find a USB thumb drive sitting on the ground. I hope everyone knows that you should absolutely not take that drive inside your office and plug it into your workstation. Everyone in software should (rightly) be screaming no right now! Real attacks have happened this way, and security orgs across the world hammer this into all employees as part of training.
But for some reason, we don’t even pause to think twice before running docker pull or npm install, even though these are arguably worse than plugging in a random USB stick! Both situations involve taking code from someone you do not trust and running it, but the docker container or NPM package will eventually make it all the way into your production environment!
Zero Trust
Traditionally, network and workload security relied on trusted “perimeters”. Firewalls, internal networks and physical security provided defense against attackers by keeping them out. This type of architecture is simple and effective when all assets are in one place, the firewall doesn’t need many holes and all hardware is on the same physical network.
Unfortunately, this isn’t true anymore. The workplace is distributed. Devices are mobile and environments are ephemeral. Enter zero-trust security. Zero-trust architecture focuses on protecting assets, not perimeters. Services authenticate users against hardware instead of network endpoints. Users authenticate with multi-factor-authentication (FIDO2, etc.) and devices authenticate with hardware-roots-of-trust (TPM2, etc.). The end result is a system focused on fine-grained access control. Instead of trusting every device on a network, you control exactly which users and systems have access to which services.
In a supply chain, artifacts travel along a series of repositories (source code or binary artifact) as they are transformed from initial commit to running artifact in a production environment and trust is typically managed at the repository-level. An organization trusts an SCM for their first-party code, and a series of artifact managers (language, container) for their third-party code. Stricter companies may require all artifacts to be mirrored into a fully-trusted first-party repository. In these scenarios, trust moves internal but remains at the repository level.
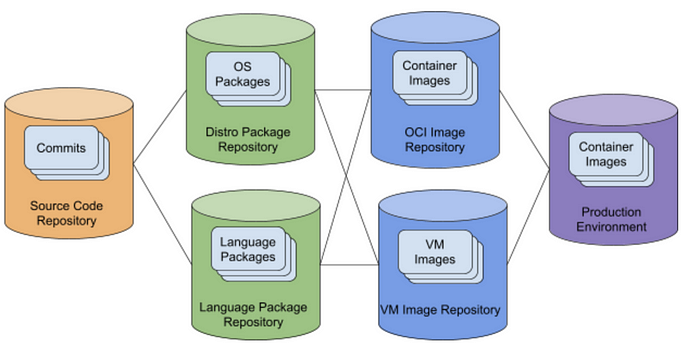
In typical open source supply-chains, a compromise in any one of these systems is enough to attack the final system. There are typically many more separate systems than depicted above, and many are run for free by open-source communities with low or zero budgets.
A Zero Trust Supply Chain moves artifact repositories out of the Trusted Compute Base. Individuals and build systems attest to source code and artifacts directly. These attestations form a verifiable chain from its origin (developer or system) to final, deployed production artifact. Artifact metadata (including rich provenance) is digitally-signed with PKI support. Signed metadata files, or attestations, are stored and accessible in a global transparency log.

Instead of trusting the systems to serve accurate package metadata, we verify each claim in the chain itself against the actors or systems that attested to them.
The Challenge With Zero Trust Supply Chain Security
Supply-chain security is very similar to network security and identity management. Instead of authenticating people or systems, we need to authenticate artifacts. There are multiple systems in use today, but all rely on cryptographic signatures and some form of PKI.
Existing PKI systems for artifact signing include distributed systems like PGP’s Web of Trust or TOFU models, centralized systems like Apple and the Play Store’s code-signing systems, as well as hierarchical CA systems like Authenticode. Newer technologies like transparency logs are also starting to serve a role, with usage in the Go modules ecosystem as well other Binary transparency implementations.

Authenticating an artifact is similar to authenticating a system or an individual in many ways, but it also differs in a few key ways that mean the existing technologies don’t map perfectly. The biggest difference is that artifacts are not “alive”. An artifact is like a rock. It cannot vouch for, or attest to its own identity like a person or system can. A person can vouch for their own identity by entering a password, touching a token or even meeting in person to show a government ID. A system can vouch for its identity by responding to a challenge (like in ACME) or using a hardware root-of-trust with something like a TPM. If you ask an artifact who it is, it just sits there like a rock.
This might sound silly, but has large implications on the way we need to design authentication systems. Cryptographic authentication systems usually rely on one party possessing a secret, and using this secret to complete challenges that prove they still have possession of this secret. If this secret is lost or stolen, the protocol fails and the user must recover their identity in some way. Well-designed systems acknowledge that secrets cannot be kept secret forever, so they include some form of automatic rotation or expiration.
This means users or systems must periodically obtain or generate new secrets to use to attest to their identity. Each protocol specifies exactly how this works (ACME for Web PKI, cookie, session or JWT expiration for user logins, etc.), but the key problem is that they require some active form of interaction from the user/system. Artifacts are just rocks sitting on the ground, so they can’t do this.
Getting Started
The problem statement was simple — why can’t you run a random binary package or container that you find on the sidewalk? Why is there no way to determine where any given container came from? Basic questions, like who built it, from what source, and how? Some great projects like In-Toto and The Update Framework have been working on this problem for years, but they were still missing a few parts that we set out to solve in Sigstore.
These missing parts were:
- an easy to use signing system
- a central discovery and storage system for build attestations
- automatic build system integrations.
Through Sigstore, TektonCD, SPIFFE/SPIRE and a few other projects, we’ve solved these missing pieces. This post shows how to put them together into one cohesive system, and how an end user can trace an artifact from a production cluster all the way back to the code that went into it.
The Pieces
Sigstore makes signing of arbitrary artifacts dead simple with the cosigntool, including built-in support for cloud KMS systems, physical HSMs, yubikey devices, and Sigstore’s free code-signing CA based on Open ID Connect.
Sigstore also provides a central binary transparency log called Rekor, based on the same technology that powers Certificate Transparency in almost every major browser today. Rekor can act as an immutable, verifiable ledger containing metadata about software artifacts that can be looked up by anyone given only an artifact hash.
On top of Rekor, we’ve also built an Attestation Transparency system, allowing for the storage and retrieval of rich In-Toto attestations that contain the full build history of any given artifact, including the exact tools, source code and build system that was used.
Finally, we’ve started to integrate all of these parts together into build systems, so it all happens automatically. TektonCD was designed with supply-chain security in mind from day one, and the Tekton Chains project has been a perfect place to experiment and add these features!
Enough words, let’s see it in action!
Tracing a Container
For this experiment, we’re going to trace an application container all the way back to the lowest level base image (FROM SCRATCH). We’ll verify signatures and attestations about every step in this build process, across multiple build systems run by different organizations!
You can follow along from your own machine by installing the crane, cosign, and rekor-cli tools, or see the commands here. The overall build process looks like this:
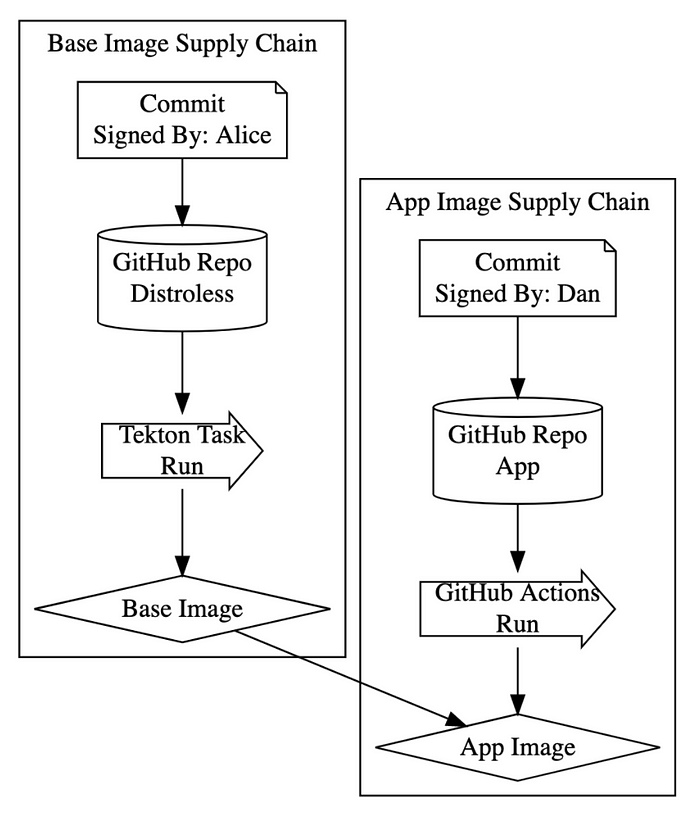
Step 1: The Application Container
The demo starts with a container image built using the ko build tool inside of a GitHub Action. We’ll verify the signatures on this application image, which are signed using an ambient token made available by the GitHub Actions platform. This token is bound to a specific invocation of the action at a specific commit, which we can lookup in the transparency log.
The container image is built from the github.com/dlorenc/hello-ko repository, and is available at ghcr.io/dlorenc/hello-ko.
We’ll start by looking up signatures for that image:
Here we can see that there is a valid signature for the image! The image was signed by an ephemeral certificate issued by the Fulcio CA, and bound to a specific GitHub Action. We can see this action in theSubject field of the certificate, and here it has been set to https://github.com/dlorenc/hello-ko/.github/workflows/build.yaml@refs/heads/main. The specific git commit the container was built at is also contained in the payload: git_sha”: “e0449b31dfa7794964fcf2370392f269962c4488.
Let’s pause briefly for effect: we’ve now looked up and cryptographically verified the exact build and commit a container image was built from! That’s pretty cool.

But that’s not all! We can check the source as well. Supply chain security is so tough to get right because there are so many different attack points in even a simple release process. The SLSA project contains a great overview and breakdown of these points, you can see them in a map here:

For this case, we’ve verified the commit something happened at, but we still don’t know if that commit should be trusted. The source code repository itself could have been compromised, or someone might have obtained permissions by accident. To solve this, we can check for commit signatures!
We’ll do this again using Rekor, by looking for signatures in the transparency log. After a bit of jq magic, we get the email address that the commit was signed by in the Subject field, my own personal one: email:lorenc.d@gmail.com
Step 2: The Base Image
So now we’ve verified the application image and the commit used to build it. We can keep going though, and look for more turtles on the way down. Most containers are built from a base image, which can also be attacked! Thanks to a recent change in the OCI, image build tools can include an annotation that points to the specific base image and digest used during a build.
We’ll lookup that annotation using crane, and find that it’s gcr,io/distroless/static:nonroot, at digest sha256:c070202f5ea785303a9f8cfc5f094d210336e3e0ef09806b2edcce3d5e223eb7:
Then, we look for signatures. We find one valid signature with a Subject of keyless@distroless.iam.gserviceaccount.com , which is the correct service account used to sign these images in the repository.
We can go a bit further here though, because the distroless images are reproducible. These images are actually built in multiple build systems to compare their hashes. One of the build systems used here is TektonCD, configured with Tekton Chains to produce In-Toto Provenance Attestations. The overall system architecture was described by Priya Wadhwa in this great blog post.
To lookup this provenance, we’ll start with the base image digest from above and search for entries in the transparency log. After some unpacking, we can find the full Tekton Provenance for the build.
This contains not only the commit the artifact was built from, but also the container image (and digests) and arguments used for every build step in the process. These images themselves can be signed and have provenance, all the way back down to SCRATCH.
Wrapping Up
Aeva Black summarized the concept very well during my talk:
Applying these concepts to supply chains and build systems allows organizations to verify trust at every link in the chain. Perimeters don’t work for networks, and they don’t work for supply chains either.
Sigstore’s global transparency log allows us to get started incrementally by enabling anyone to publish metadata and attestations to a location that can be discovered by downstream users. As this graph fills out with more projects writing data as they build and release, we can strengthen the overall open source ecosystem. These same concepts apply internally to organizations, with concepts like innersource helping companies share code across teams and business units.
Combining these attestations with tightly integrated policy systems is the next step in automating compliance and tamper-resistance. If you’re interested in helping out, hop into the Sigstore slack or reach out on Twitter!
And if you’re interested in learning more about supply chain security register for SupplyChainSecurityCon happening on October 11 in co-location with KubeCon.