Originally posted on the Jenkins blog by Martin d’Anjou, Jeff Pearce, Oleg Nenashev, Marky Jackson
Google Summer of Code is much more than a summer internship program, it is a year-round effort for the organization and some community members. Now, after the DevOps World | Jenkins World conference in Lisbon and final retrospective meetings, we can say that GSoC 2019 is officially over. We would like to start by thanking all participants: students, mentors, subject matter experts and all other contributors who proposed project ideas, participated in student selection, in community bonding and in further discussions and reviews. Google Summer of Code is a major effort which would not be possible without the active participation of the Jenkins community.
In this blogpost we would like to share the results and our experience from the previous year.
Results
Five GSoC projects were successfully completed this year: Role Strategy Plugin Performance Improvements, Plugins Installation Manager CLI Tool/Library, Working Hours Plugin – UI Improvements, Remoting over Apache Kafka with Kubernetes features, Multi-branch Pipeline support for Gitlab SCM. We will talk about the projects a little later in the document.

Project details
We held the final presentations as Jenkins Online Meetups in late August and Google published the results on Sept 3rd. The final presentations can be found here: Part 1, Part 2, Part 3. We also presented the 2019 Jenkins GSoC report at the DevOps World | Jenkins World San Francisco and at the DevOps World | Jenkins World 2019 Lisbon conferences.
In the following sections, we present a brief summary of each project, links to the coding phase 3 presentations, and to the final products.
Role Strategy Plugin Performance Improvements
Role Strategy Plugin is one of the most widely used authorization plugins for Jenkins, but it has never been famous for performance due to architecture issues and regular expression checks for project roles. Abhyudaya Sharma was working on this project together with hist mentors: Oleg Nenashev, Runze Xia and Supun Wanniarachchi. He started the project from creating a new Micro-benchmarking Framework for Jenkins Plugins based on JMH, created benchmarks and achieved a 3501% improvement on some real-world scenarios. Then he went further and created a new Folder-based Authorization Strategy Plugin which offers even better performance for Jenkins instances where permissions are scoped to folders. During his project Abhyudaya also fixed the Jenkins Configuration-as-Code support in Role Strategy and contributed several improvements and fixes to the JCasC Plugin itself.
- Project page
- Blog posts: Micro-benchmarking Framework for Jenkins Plugins, Introducing new Folder Authorization Plugin, Performance Improvements to Role Strategy Plugin
- Final evaluation: slides, video
- Source code: Role Strategy Plugin, Folder Authorization Plugin
Plugins Installation Manager CLI Tool/Library
Natasha Stopa was working on a new CLI tool for plugin management, which should unify features available in other tools like install-plugins.sh in Docker images. It also introduced many new features like YAML configuration format support, listing of available updates and security fixes. The newly created tool should eventually replace the previous ones. Natasha’s mentors: Kristin Whetstone, Jon Brohauge and Arnab Banerjee. Also, many contributors from Platform SIG and JCasC plugin team joined the project as a key stakeholders and subject-matter experts.
- Project page
- Blog posts: alpha release announcement, coding phase 2 updates
- Final evaluation: slides, video
- Source code: Plugin installation manager tool
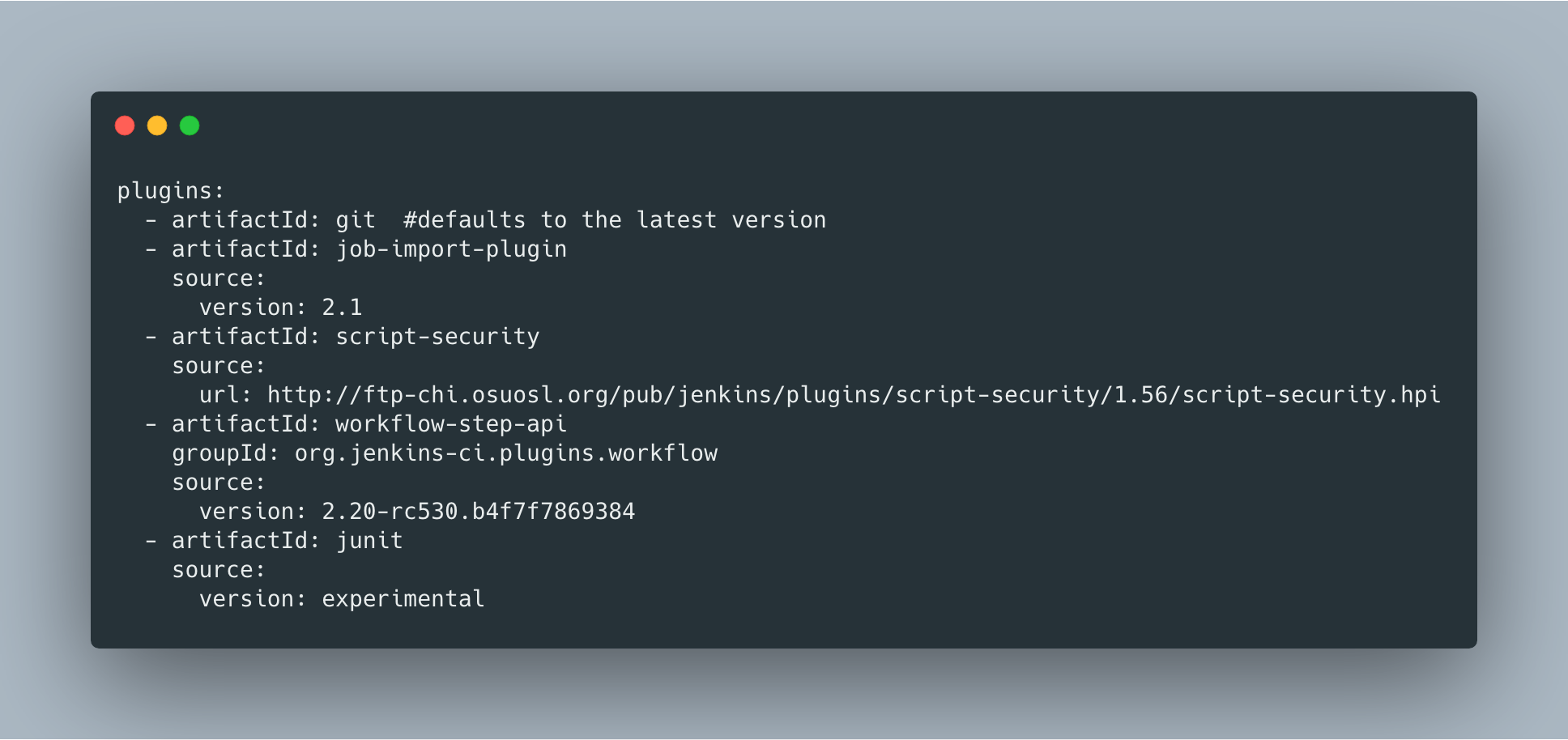
Working Hours Plugin – UI Improvements
Jenkins UI and frontend framework are a common topic in the Jenkins project, especially in recent months after the new UX SIG was established. Jack Shen was working on exploring new ways to build Jenkins Web UI together with his mentor Jeff Pearce. Jack updated the Working Hours Plugin to use UI controls provided by standard React libraries. Then he documented his experienced and created template for plugins with React-based UI.
- Project page
- Blog posts: Updates on Working Hours Plugin UI, React Plugin Template
- Final evaluation: slides, video
- Source code: Working Hours Plugin, Template for Jenkins plugins with React-based UI
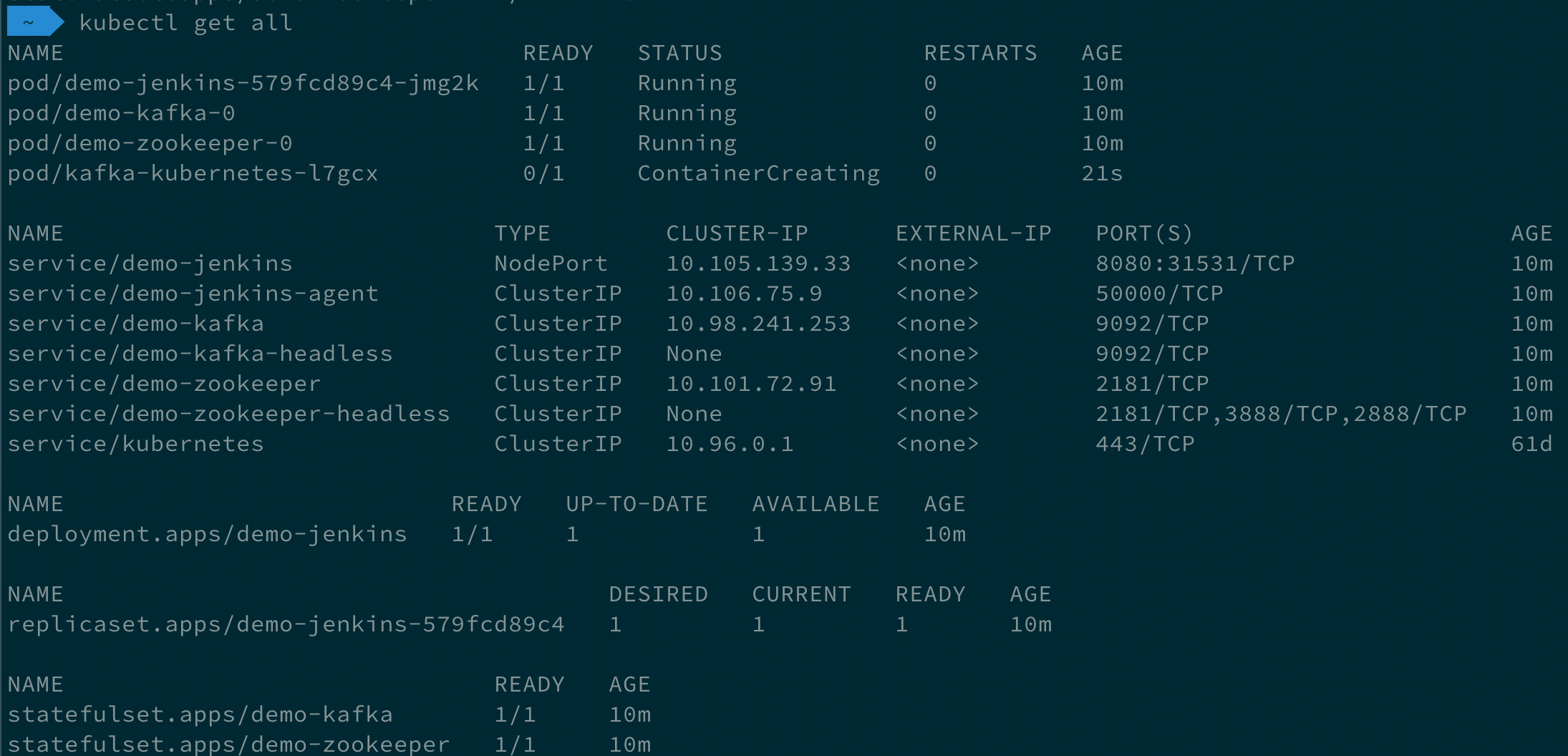
Remoting over Apache Kafka with Kubernetes features
Long Le Vu Nguyen was working on extended Kubernetes support in the Remoting over Apache Kafka Plugin. His mentors were Andrey Falco and Pham vu Tuan who was our GSoC 2018 student and the plugin creator. During this project Long has added a new agent launcher which provisions Jenkins agents in Kubernetes and connects them to the master. He also created a Cloud API implementation for it and a new Helm chart which can provision Jenkins as entire system in Kubernetes, with Apache Kafka enabled by default. All these features were released in Remoting over Apache Kafka Plugin 2.0.
- Project page
- Blog post for [Remoting over Apache Kafka Plugin 2.0
- Final evaluation: slides, video
- Plugin source code
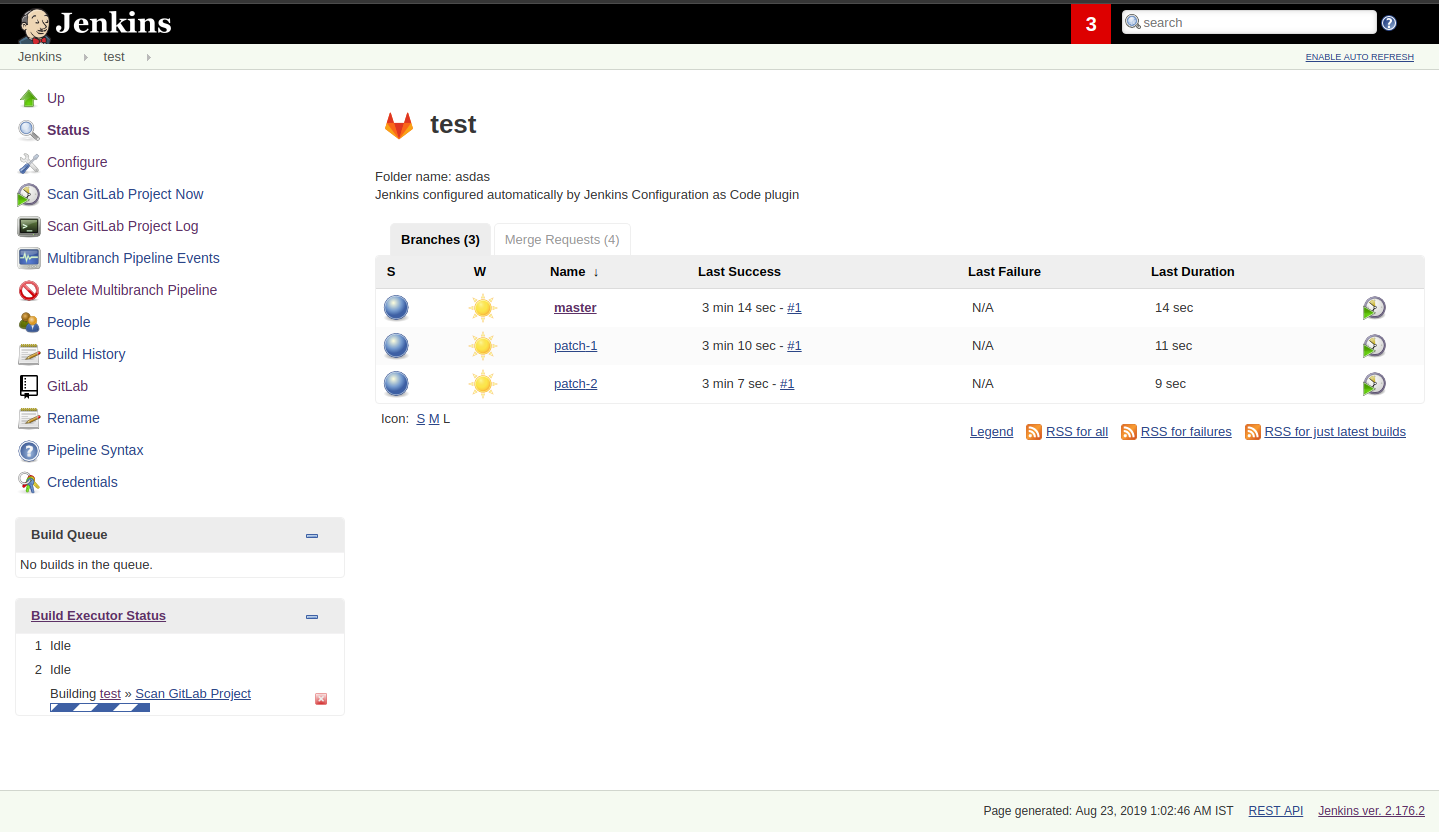
Multi-branch Pipeline support for Gitlab SCM
Parichay Barpanda was working on the new GitLab Branch Source Plugin with Multi-branch Pipeline Jobs and Folder Organisation support. His mentors were Marky Jackson-Taulia, Justin Harringa, Zhao Xiaojie and Joseph Petersen. The plugin scans the projects, importing the pipeline jobs it identifies based on the criteria provided. After a project is imported, Jenkins immediately runs the jobs based on the Jenkinsfile pipeline script and notifies the status to GitLab Pipeline Status. This plugin also provides GitLab server configuration which can be configured in Configure System or via Jenkins Configuration as Code (JCasC). read more about this project in the GitLab Branch Source 1.0 announcement.
Projects which were not completed
Not all projects have been completed this year. We were also working on Artifact Promotion plugin for Jenkins Pipeline and on Cloud Features for External Workspace Manager Plugin, but unfortunately both projects were stopped after coding phase 1. Anyway, we got a lot of experience and takeaways in these areas (see linked Jira tickets!. We hope that these stories will be implemented by Jenkins contributors at some point. Google Summer of Code 2020 maybe?
Running the GSoC program at our organization level
Here are some of the things our organization did before and during GSoC behind the scenes. To prepare for the influx of students, we updated all our GSoC pages and wrote down all the knowledge we accumulated over the years of running the program. We started preparing in October 2018, long before the official start of the program. The main objective was to address the feedback we got during GSoC 2018 retrospectives.
Project ideas. We started gathering project ideas in the last months of 2018. We prepared a list of project ideas in a Google doc, and we tracked ownership of each project in a table of that document. Each project idea was further elaborated in its own Google doc. We find that when projects get complicated during the definition phase, perhaps they are really too complicated and should not be done.
Since we wanted all the project ideas to be documented the same way, we created a template to guide the contributors. Most of the project idea documents were written by org admins or mentors, but occasionally a student proposed a genuine idea. We also captured contact information in that document such as GitHub and Gitter handles, and a preliminary list of potential mentors for the project. We embedded all the project documents on our website.
Mentor and student guidelines. We updated the mentor information page with details on what we expect mentors to do during the program, including the number of hours that are expected from mentors, and we even have a section on preventing conflict of interest. When we recruit mentors, we point them to the mentor information page.
We also updated the student information page. We find this is a huge time saver as every student contacting us has the same questions about joining and participating in the program. Instead of re-explaining the program each time, we send them a link to those pages.
Application phase. Students started to reach out very early on as well, many weeks before GSoC officially started. This was very motivating. Some students even started to work on project ideas before the official start of the program.
Project selection. This year the org admin team had some very difficult decisions to make. With lots of students, lots of projects and lots of mentors, we had to request the right number of slots and try to match the projects with the most chances of success. We were trying to form mentor teams at the same time as we were requesting the number of slots, and it was hard to get responses from all mentors in time for the deadline. Finally we requested fewer slots than we could have filled. When we request slots, we submit two numbers: a minimum and a maximum. The GSoC guide states that:
- The minimum is based on the projects that are so amazing they really want to see these projects occur over the summer,
- and the maximum number should be the number of solid and amazing projects they wish to mentor over the summer.
We were awarded minimum. So we had to make very hard decisions: we had to decide between “amazing” and “solid” proposals. For some proposals, the very outstanding ones, it’s easy. But for the others, it’s hard. We know we cannot make the perfect decision, and by experience, we know that some students or some mentors will not be able to complete the program due to uncontrollable life events, even for the outstanding proposals. So we have to make the best decision knowing that some of our choices won’t complete the program.
Community Bonding. We have found that the community bonding phase was crucial to the success of each project. Usually projects that don’t do well during community bonding have difficulties later on. In order to get students involved in the community better, almost all projects were handled under the umbrella of Special Interest Groups so that there were more stakeholders and communications.
Communications. Every year we have students who contact mentors via personal messages. Students, if you are reading this, please do NOT send us personal messages about the projects, you will not receive any preferential treatment. Obviously, in open source we want all discussions to be public, so students have to be reminded of that regularly. In 2019 we are using Gitter chat for most communications, but from an admin point of view this is more fragmented than mailing lists. It is also harder to search. Chat rooms are very convenient because they are focused, but from an admin point of view, the lack of threads in Gitter makes it hard to get an overview. Gitter threads were added recently (Nov 2019) but do not yet work well on Android and iOS. We adopted Zoom Meetings towards the end of the program and we are finding it easier to work with than Google Hangouts.
Status tracking. Another thing that was hard was to get an overview of how all the projects were doing once they were running. We made extensive use of Google sheets to track lists of projects and participants during the program to rank projects and to track statuses of project phases (community bonding, coding, etc.). It is a challenge to keep these sheets up to date, as each project involves several people and several links. We have found it time consuming and a bit hard to keep these sheets up to date, accurate and complete, especially up until the start of the coding phase.
Perhaps some kind of objective tracking tool would help. We used Jenkins Jira for tracking projects, with each phase representing a separate sprint. It helped a lot for successful projects. In our organization, we try to get everyone to beat the deadlines by a couple of days, because we know that there might be events such as power outages, bad weather (happens even in Seattle!), or other uncontrolled interruptions, that might interfere with submitting project data. We also know that when deadlines coincide with weekends, there is a risk that people may forget.
Retrospective. At the end of our project, we also held a retrospective and captured some ideas for the future. You can find the notes here. We already addressed the most important comments in our documentation and project ideas for the next year.
Recognition
Last year, we wanted to thank everyone who participated in the program by sending swag. This year, we collected all the mailing addresses we could and sent to everyone we could the 15-year Jenkins special edition T-shirt, and some stickers. This was a great feel good moment. I want to personally thank Alyssa Tong her help on setting aside the t-shirt and stickers.

Mentor summit
Each year Google invites two or more mentors from each organization to the Google Summer of Code Mentor Summit. At this event, hundreds of open-source project maintainers and mentors meet together and have unconference sessions targeting GSoC, community management and various tools. This year the summit was held in Munich, and we sent Marky Jackson and Oleg Nenashev as representatives there.
Apart from discussing projects and sharing chocolate, we also presented Jenkins there, conducted a lightning talk and hosted the unconference session about automation bots for GitHub. We did not make a team photo there, so try to find Oleg and Marky on this photo:

GSoC Team at DevOps World | Jenkins World
We traditionally use GSoC organization payments and travel grants to sponsor student trips to major Jenkins-related events. This year four students traveled to the DevOps World | Jenkins World conferences in San-Francisco and Lisbon. Students presented their projects at the community booth and at the contributor summits, and their presentations got a lot of traction in the community!
Thanks a lot to Google and CloudBees who made these trips possible. You can find a travel report from Natasha Stopa here, more travel reports are coming soon.


Conclusion
This year, five projects were successfully completed. We find this to be normal and in line with what we hear from other participating organizations.
Taking the time early to update our GSoC pages saved us a lot of time later because we did not have to repeat all the information every time someone contacted us. We find that keeping track of all the mentors, the students, the projects, and the meta information is a necessary but time consuming task. We wish we had a tool to help us do that. Coordinating meetings and reminding participants of what needs to be accomplished for deadlines is part of the cheerleading aspect of GSoC, we need to keep doing this.
Lastly, I want to thank again all participants, we could not do this without you. Each year we are impressed by the students who do great work and bring great contributions to the Jenkins community.
GSoC 2020?
Yes, there will be Google Summer of Code 2020! We plan to participate, and we are looking for project ideas, mentors and students. Jenkins GSoC pages have been already updated towards the next year, and we invite everybody interested to join us next year!